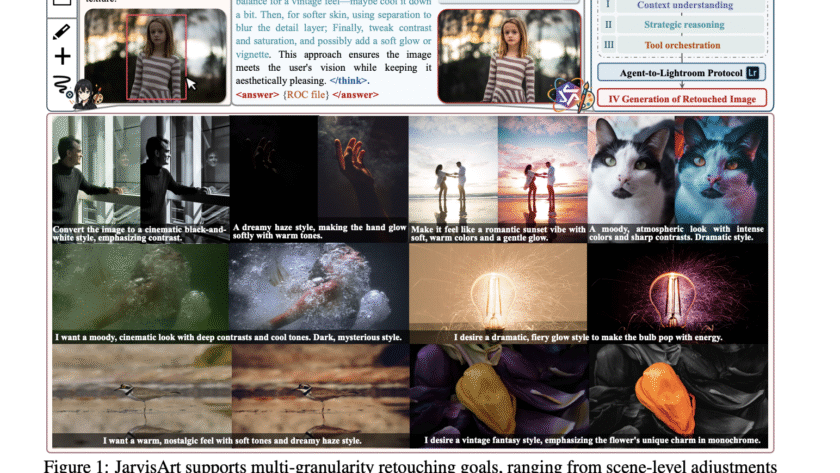
Bridging the Gap Between Artistic Intent and Technical Execution
Photo retouching is a core aspect of digital photography, enabling users to manipulate image elements such as tone, exposure, and contrast to create visually compelling content. Whether for professional purposes or personal expression, users often seek to enhance images in ways that align with specific aesthetic…