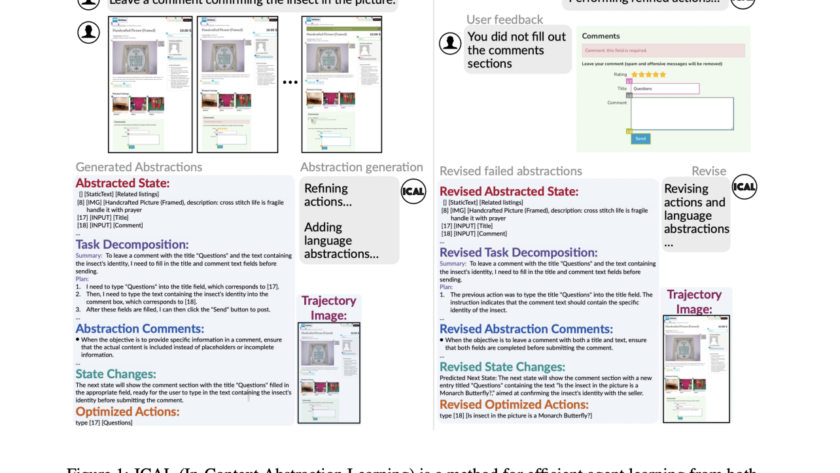
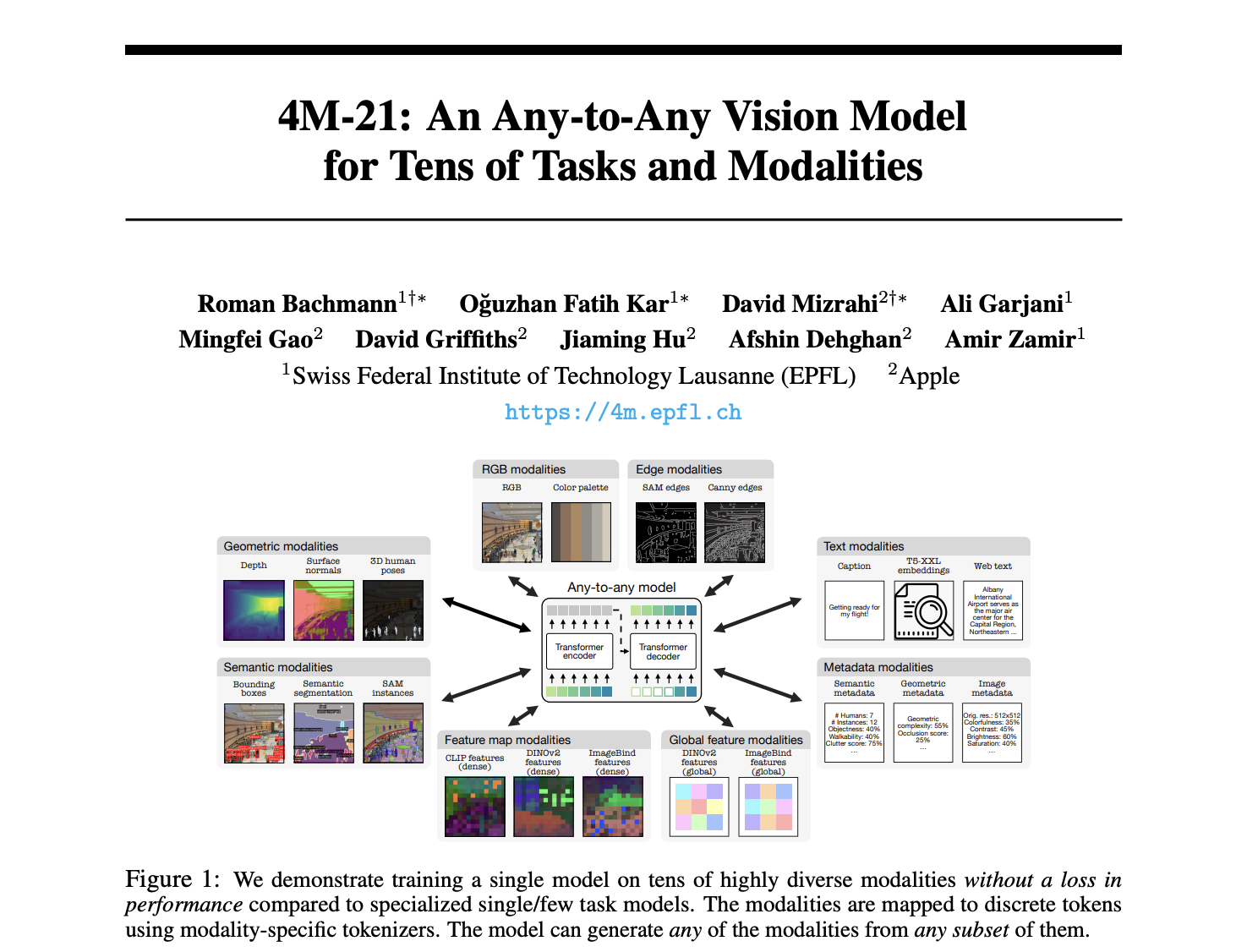
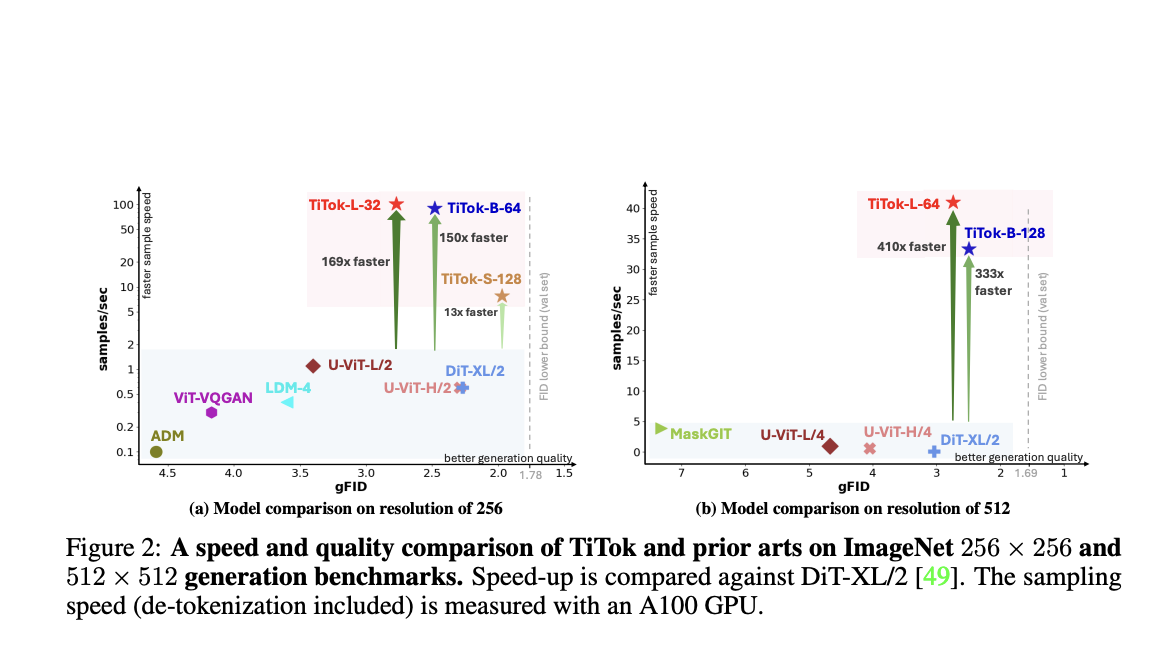
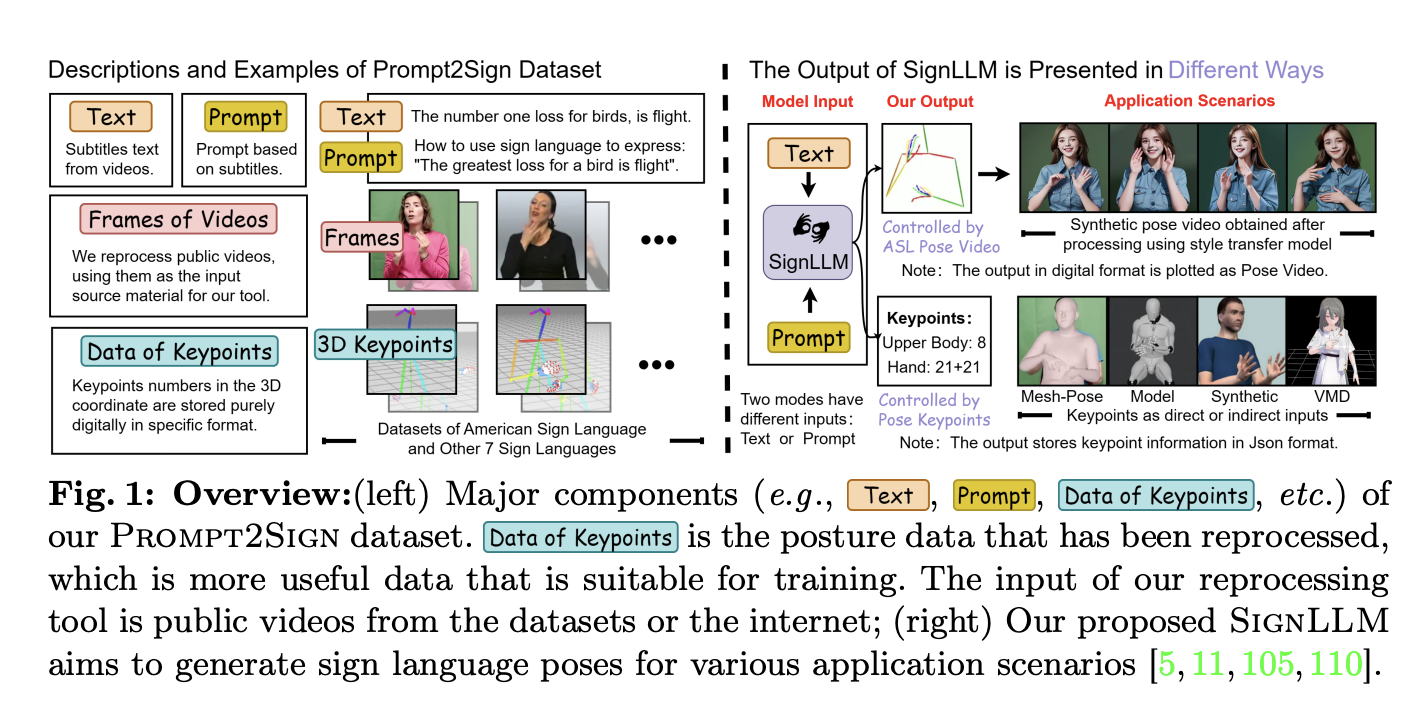
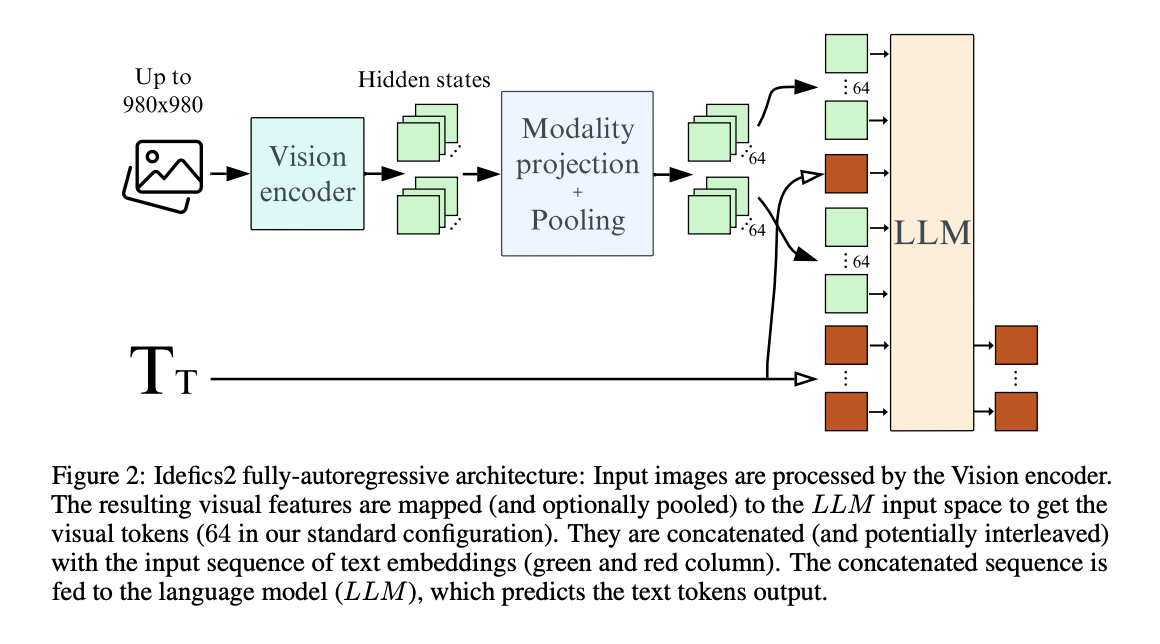
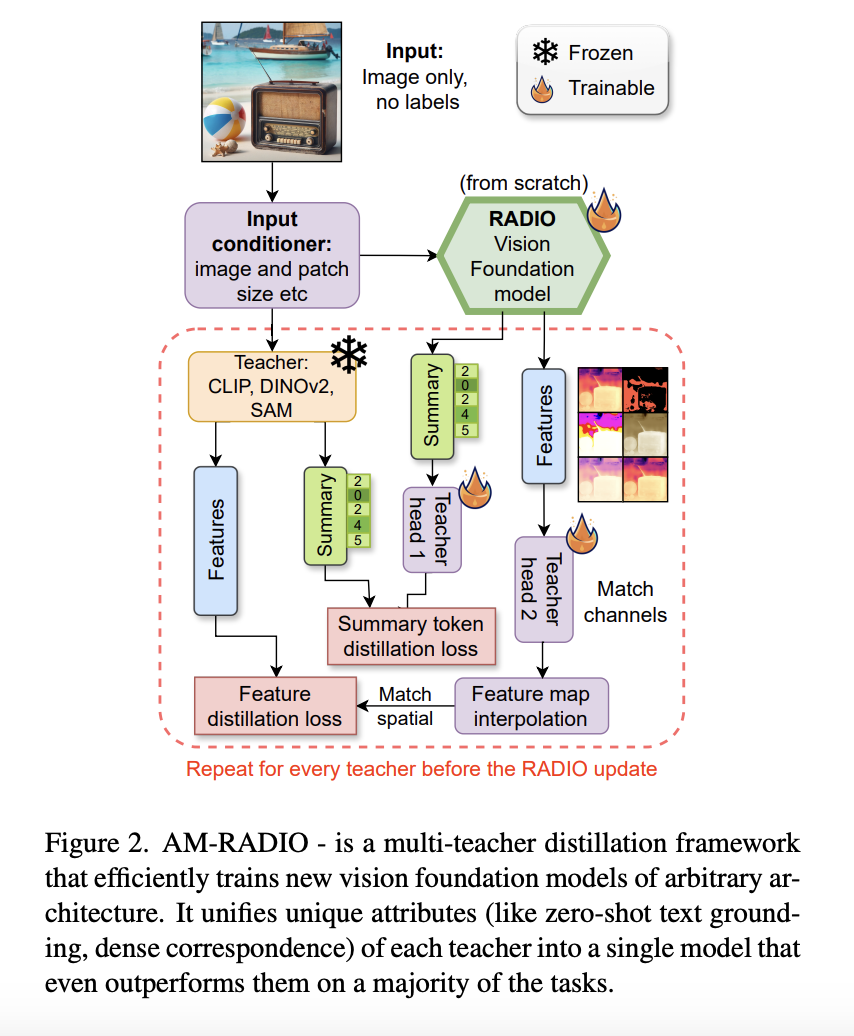
Humans are versatile; they can quickly apply what they’ve learned from little examples to larger contexts by combining new and old information. Not only can they foresee possible setbacks and determine what is important for success, but they swiftly learn to adjust to different situations by practicing and receiving feedback on what works. This process…