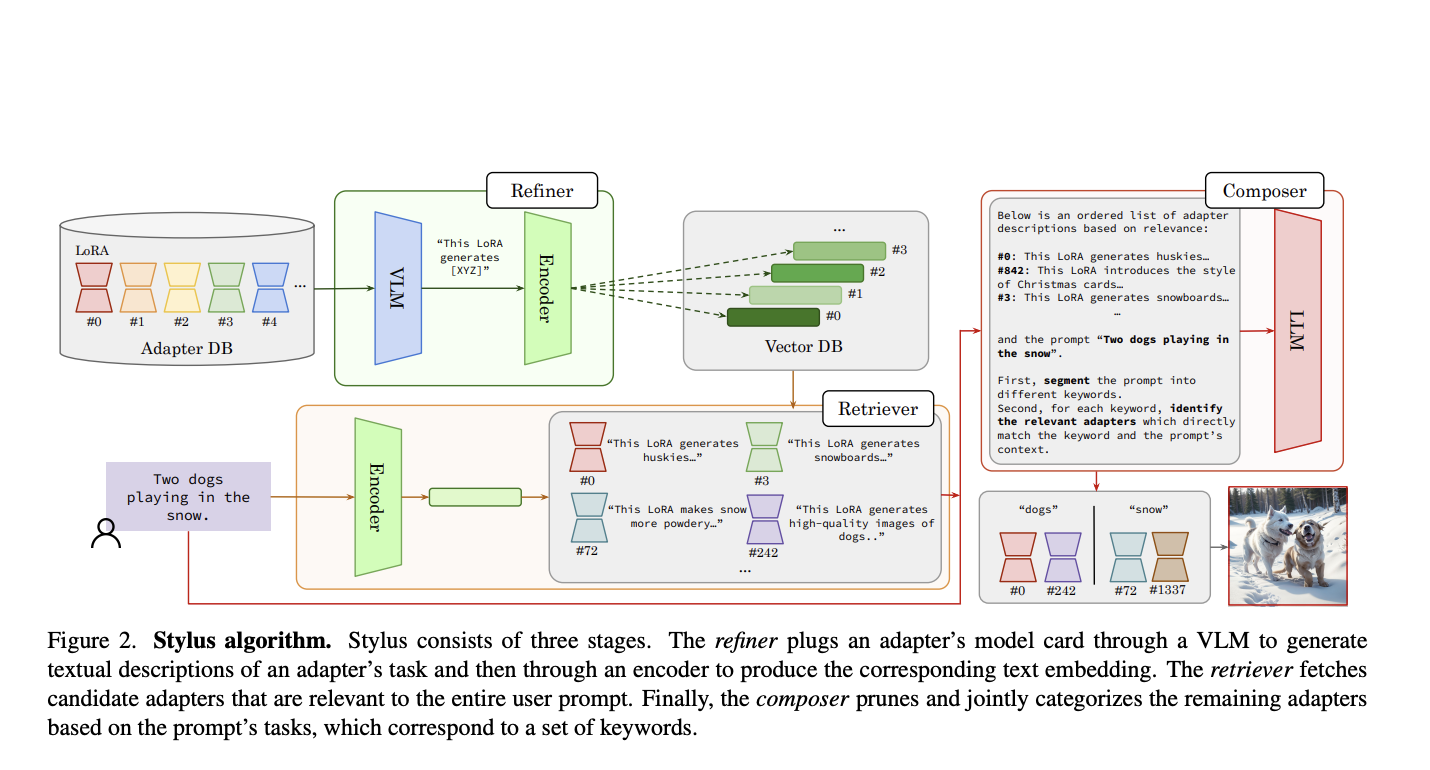
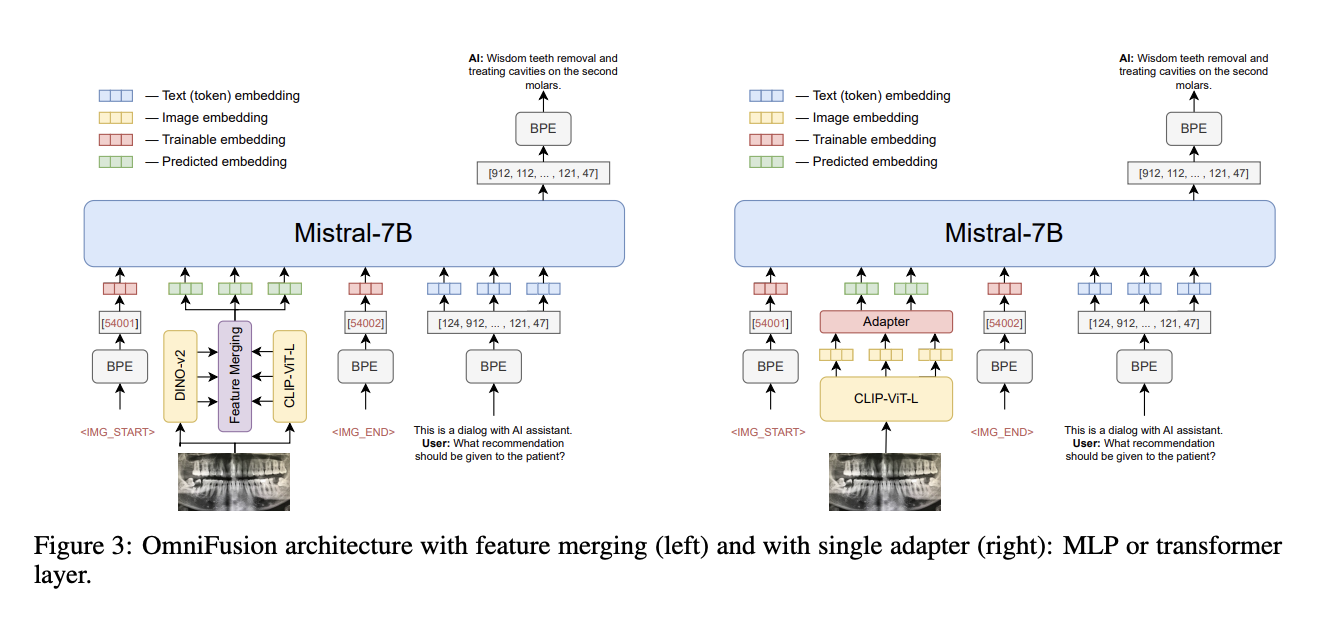
Adopting finetuned adapters has become a cornerstone in generative image models, facilitating customized image creation while minimizing storage requirements. This transition has catalyzed the development of expansive open-source platforms, fostering communities to innovate and exchange various adapters and model checkpoints, thereby propelling the proliferation of creative AI art. With over 100,000 adapters now available, the…