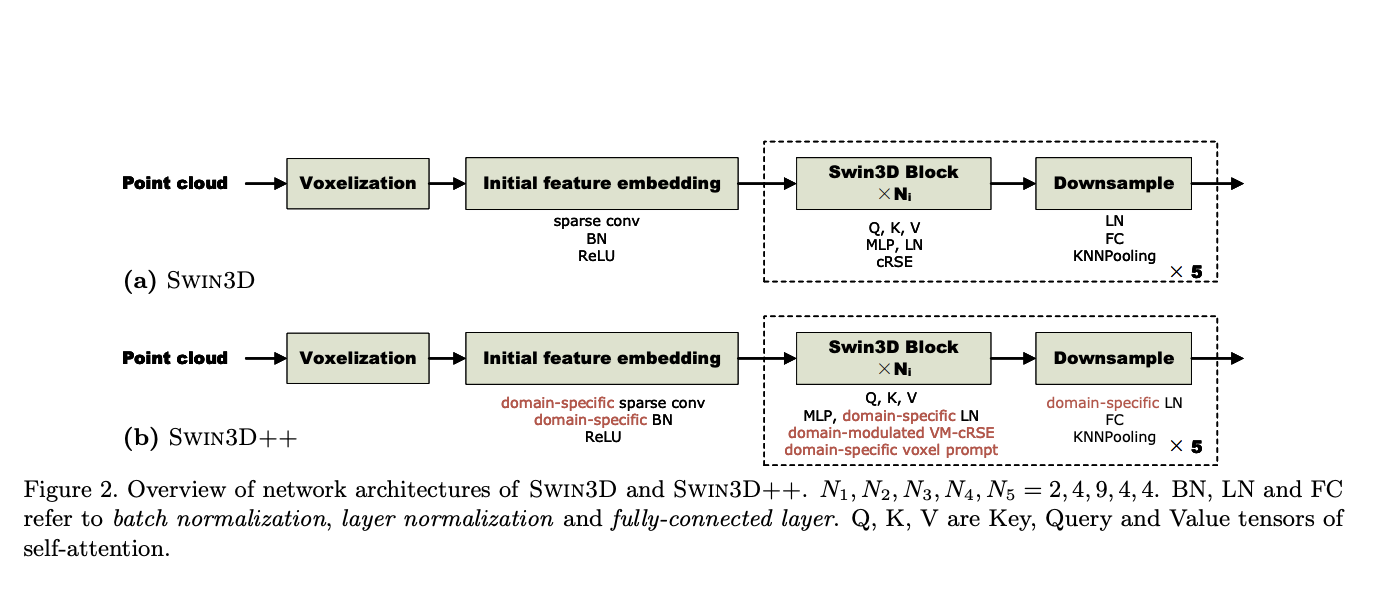
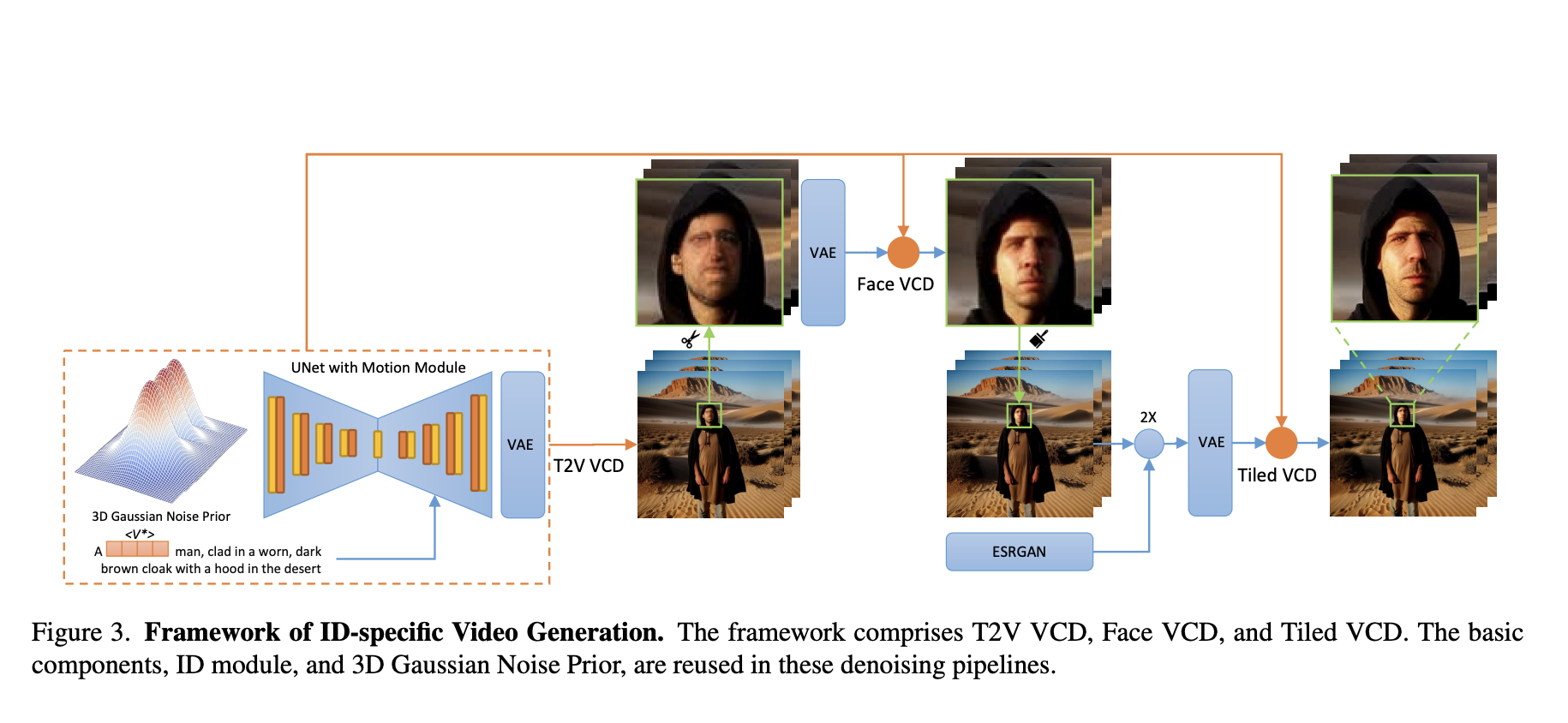
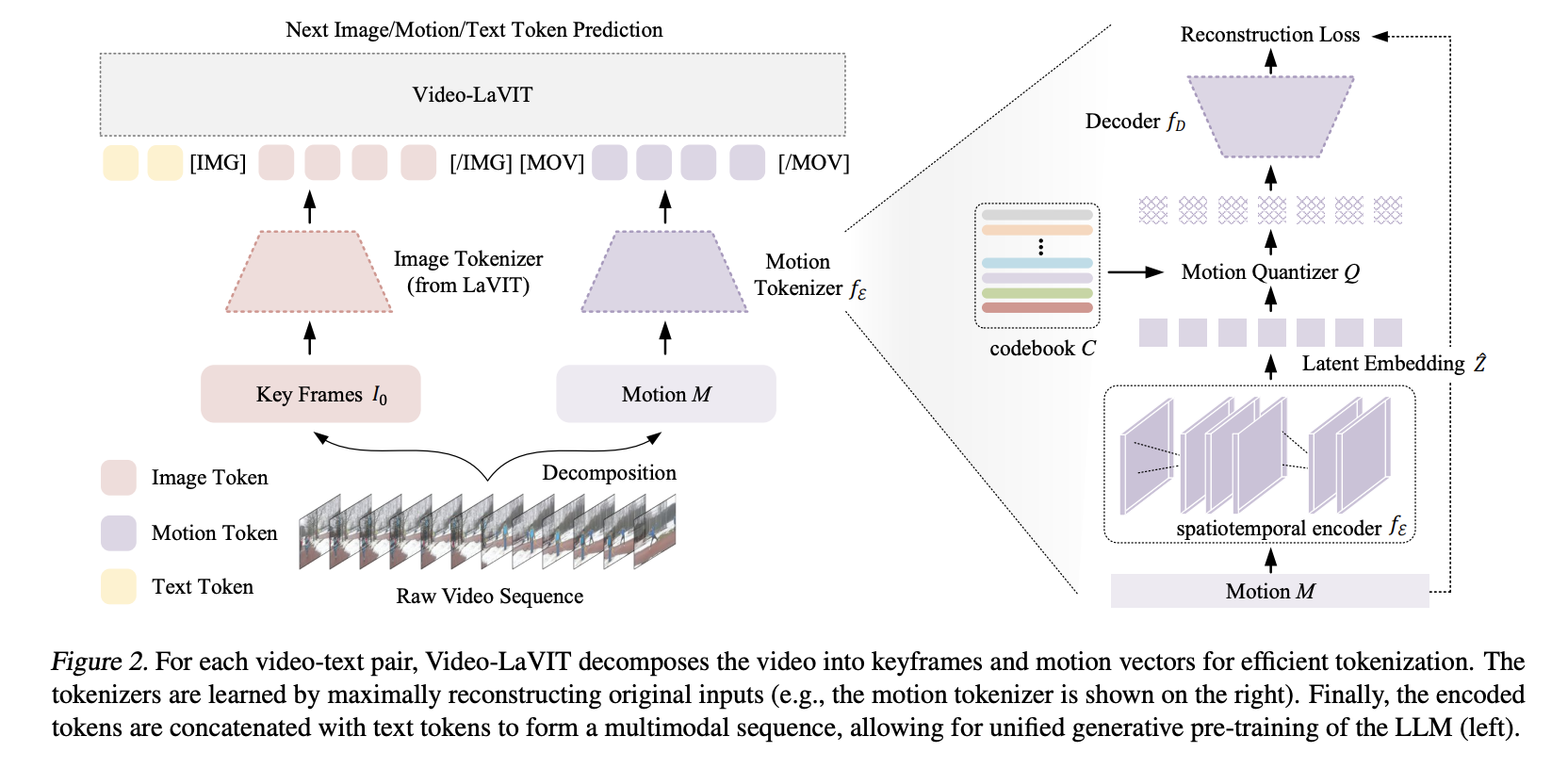
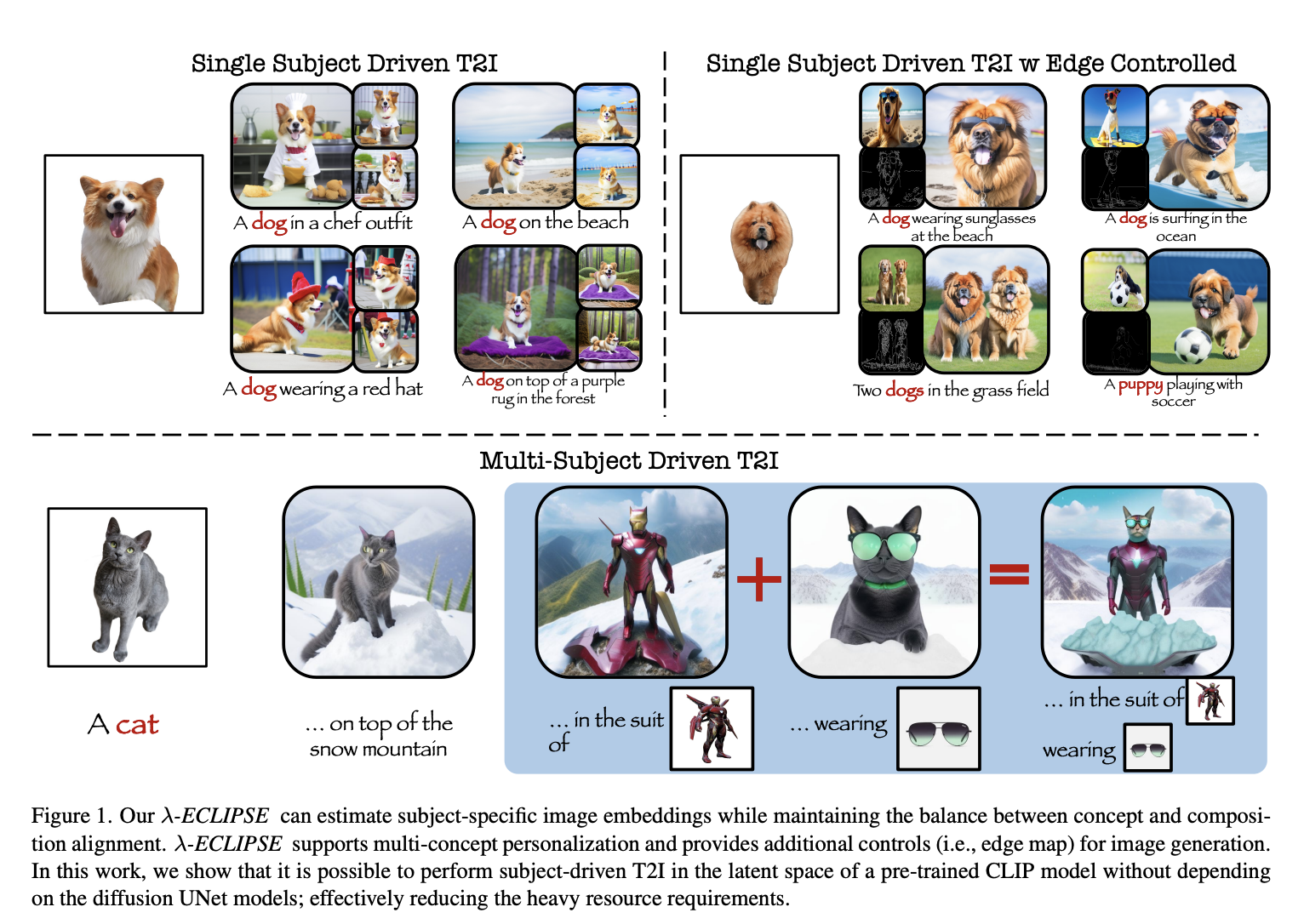
Point clouds serve as a prevalent representation of 3D data, with the extraction of point-wise features being crucial for various tasks related to 3D understanding. While deep learning methods have made significant strides in this domain, they often rely on large and diverse datasets to enhance feature learning, a strategy commonly employed in natural language…