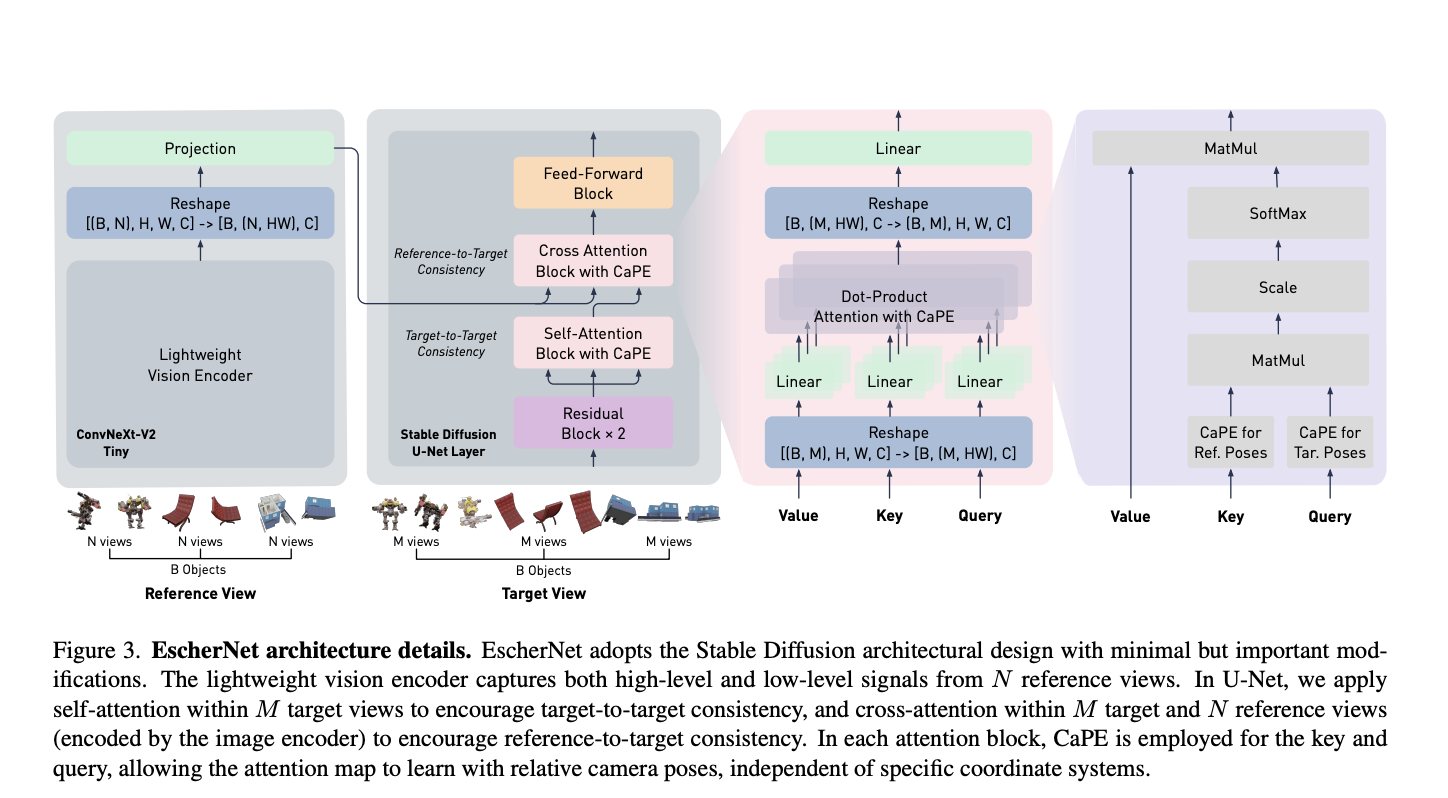
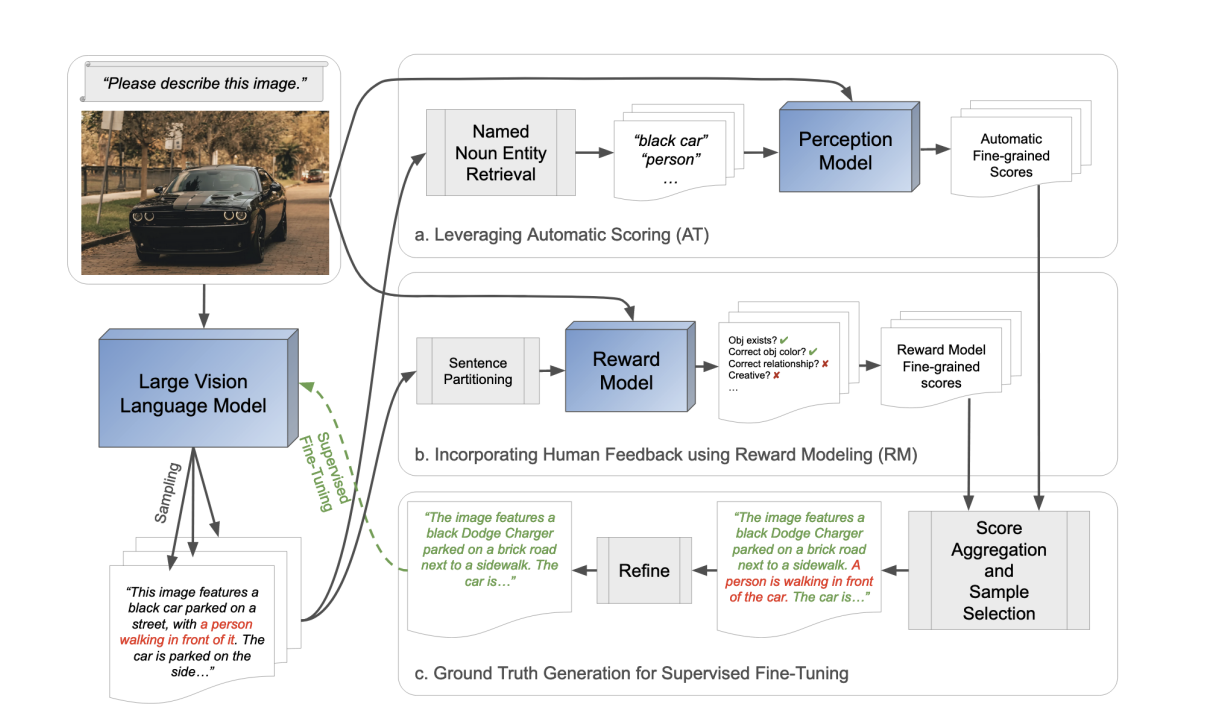
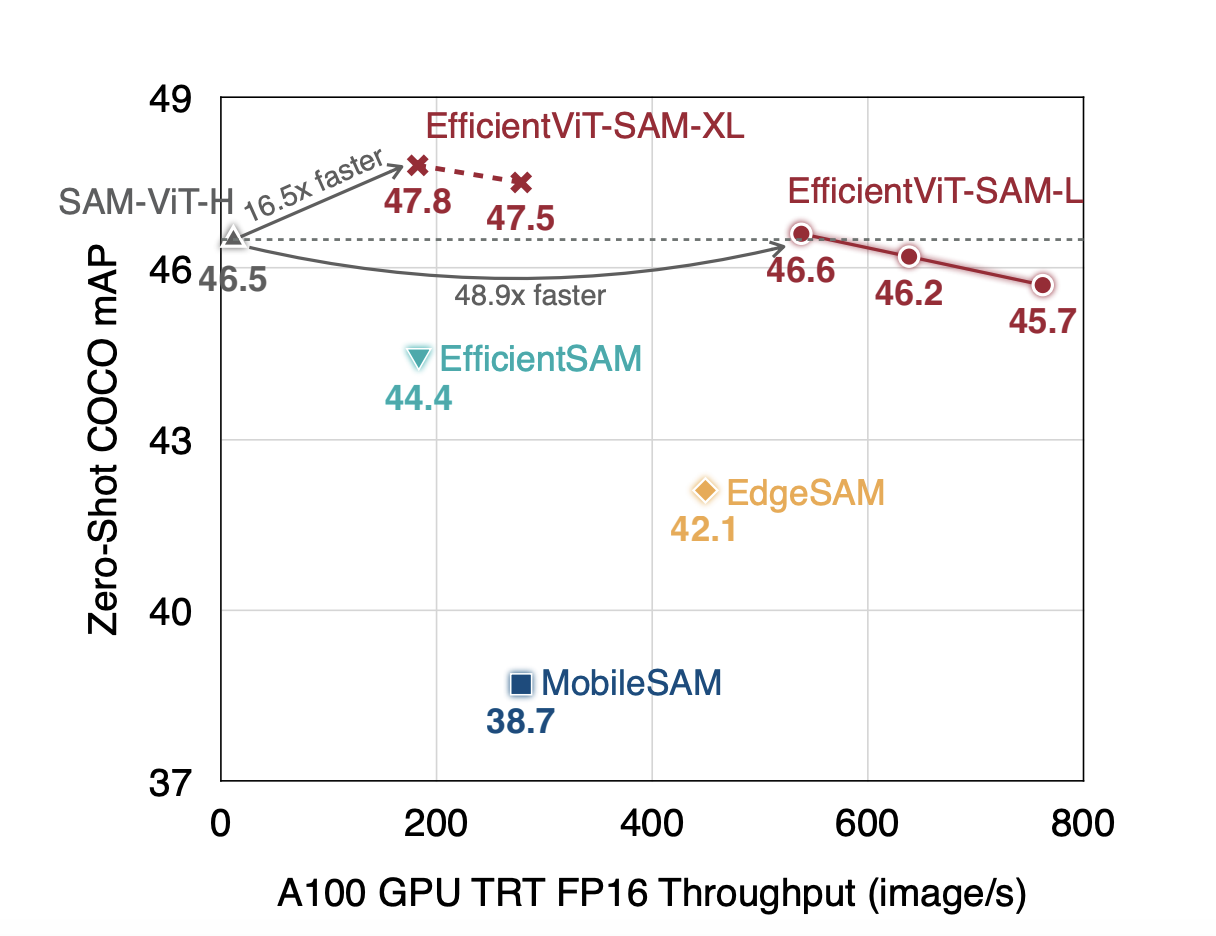
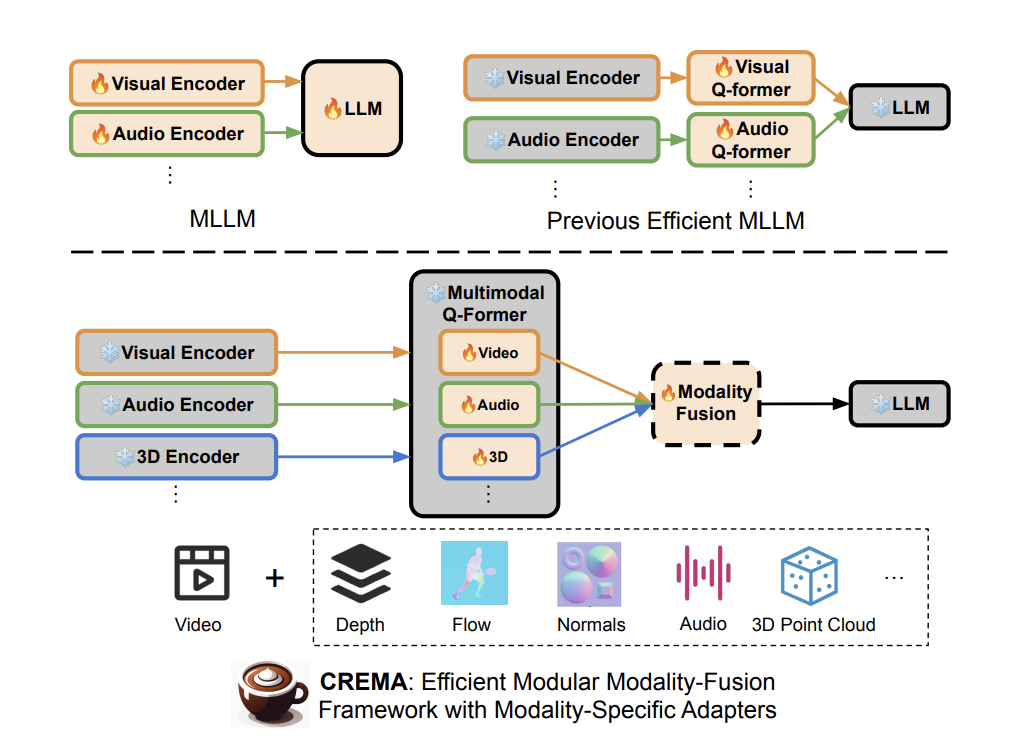
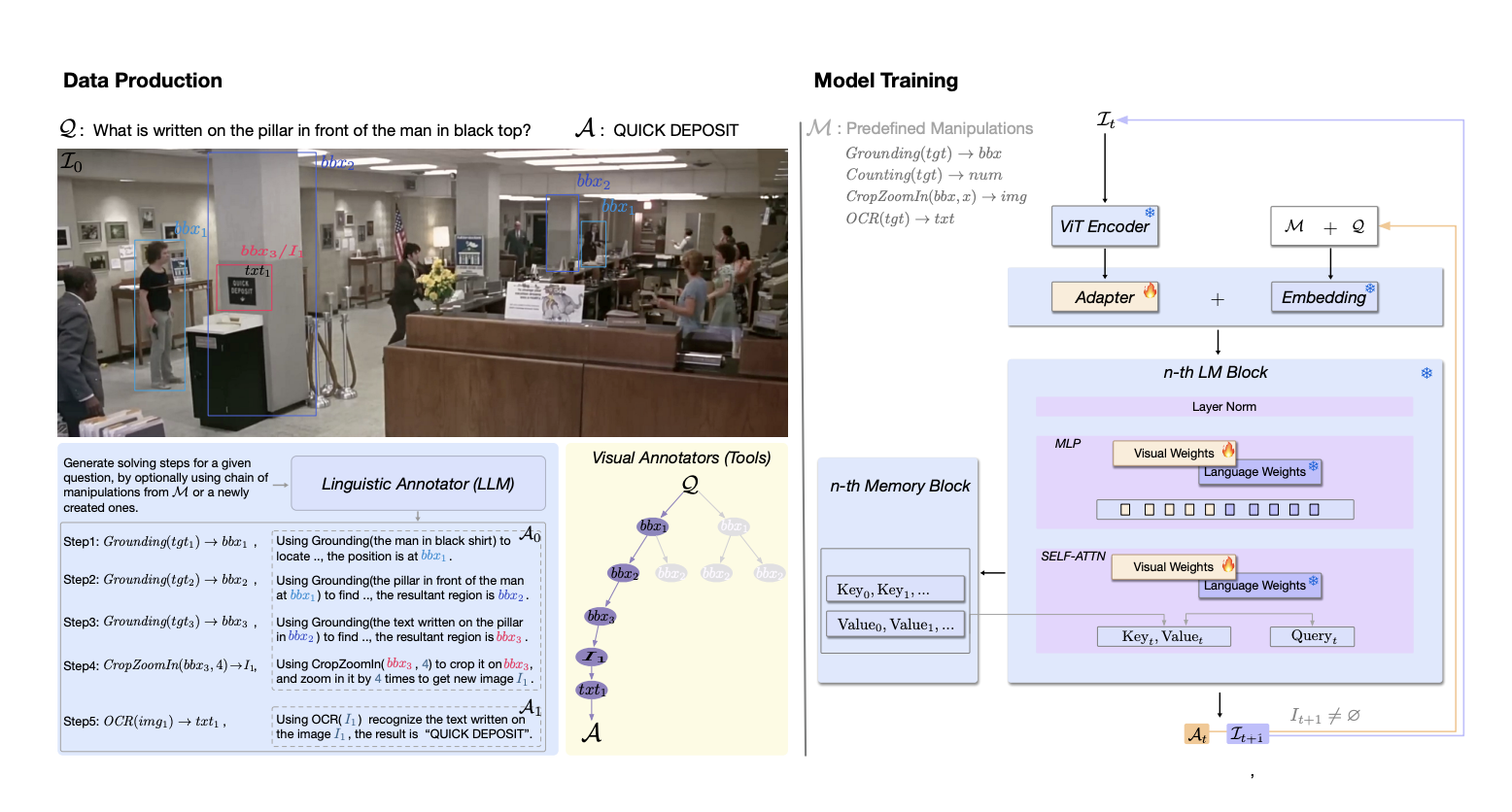
The task of view synthesis is essential in both computer vision and graphics, enabling the re-rendering of scenes from various viewpoints akin to the human eye. This capability is vital for everyday tasks and fosters creativity by allowing the envisioning and crafting of immersive objects with depth and perspective. Researchers at Dyson Robotics Lab aim…