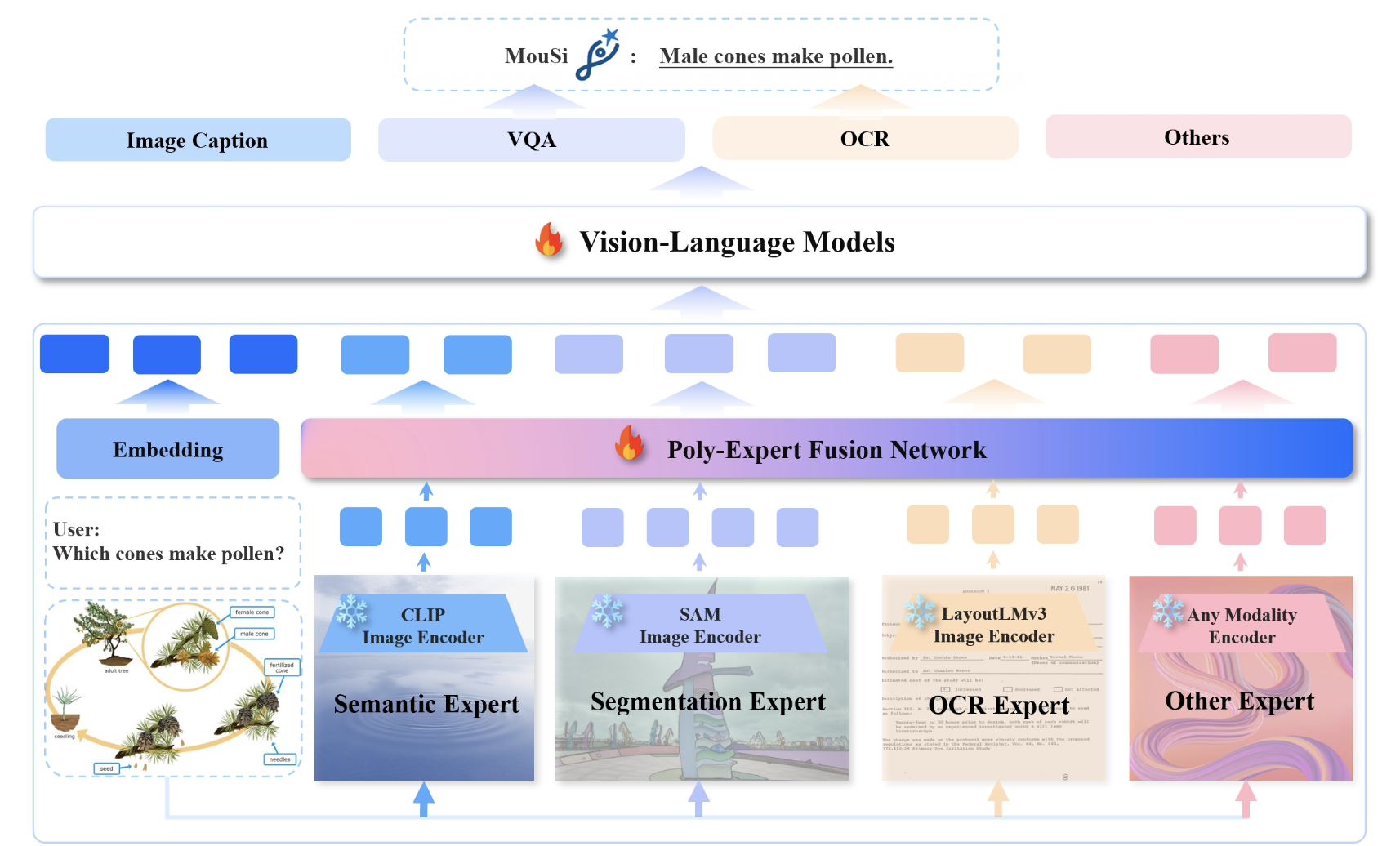
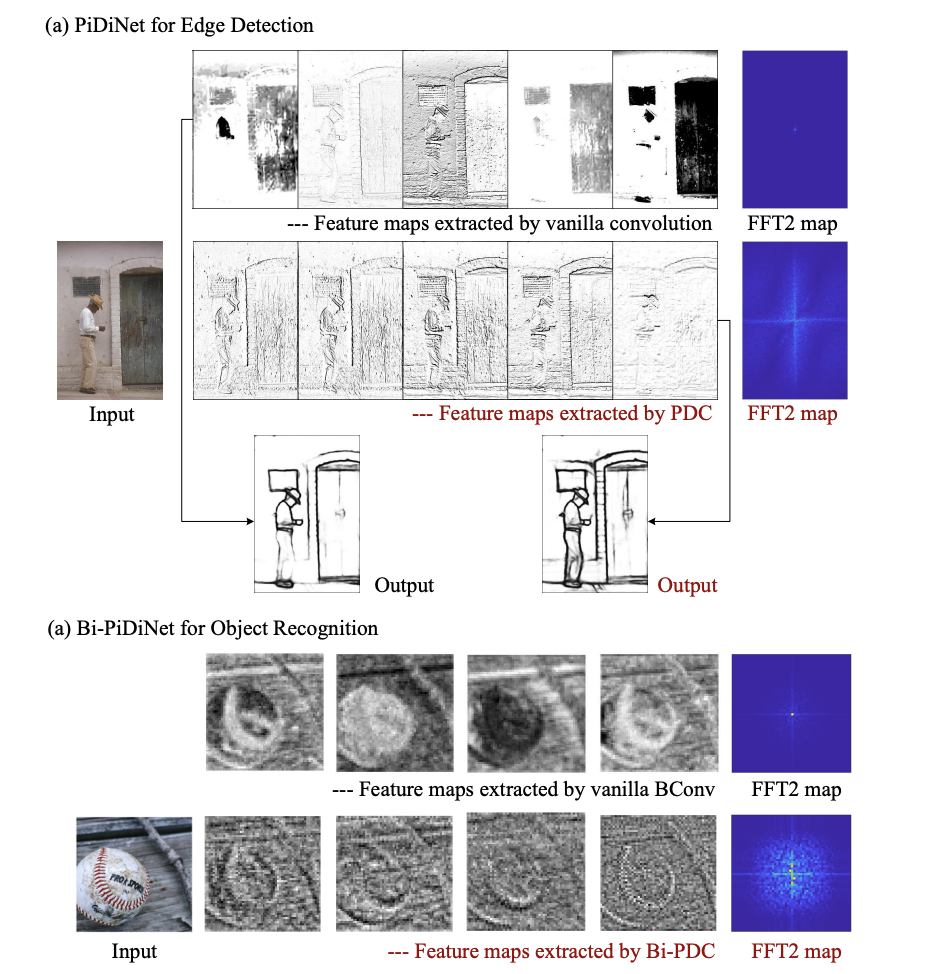
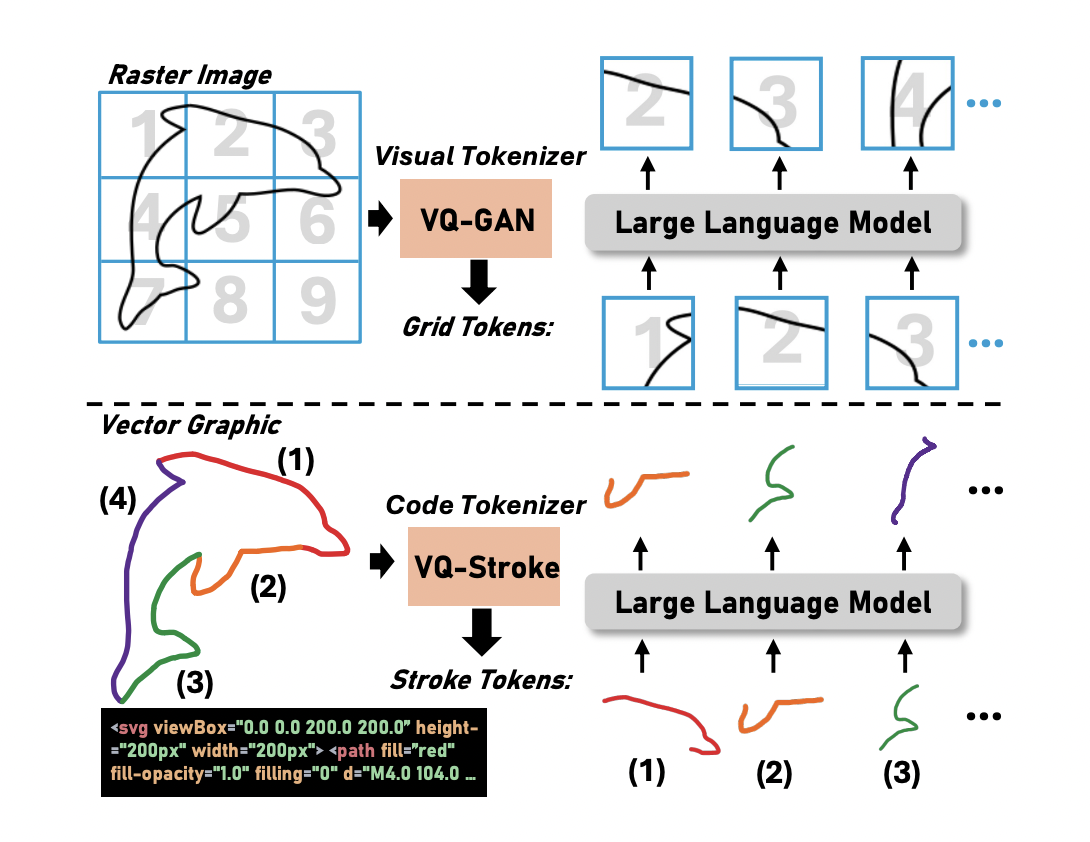
Personalized image generation is the process of generating images of certain personal objects in different user-specified contexts. For example, one may want to visualize the different ways their pet dog would look in different scenarios. Apart from personal experiences, this method also has use cases in personalized storytelling, interactive designs, etc. Although current text-to-image generation…