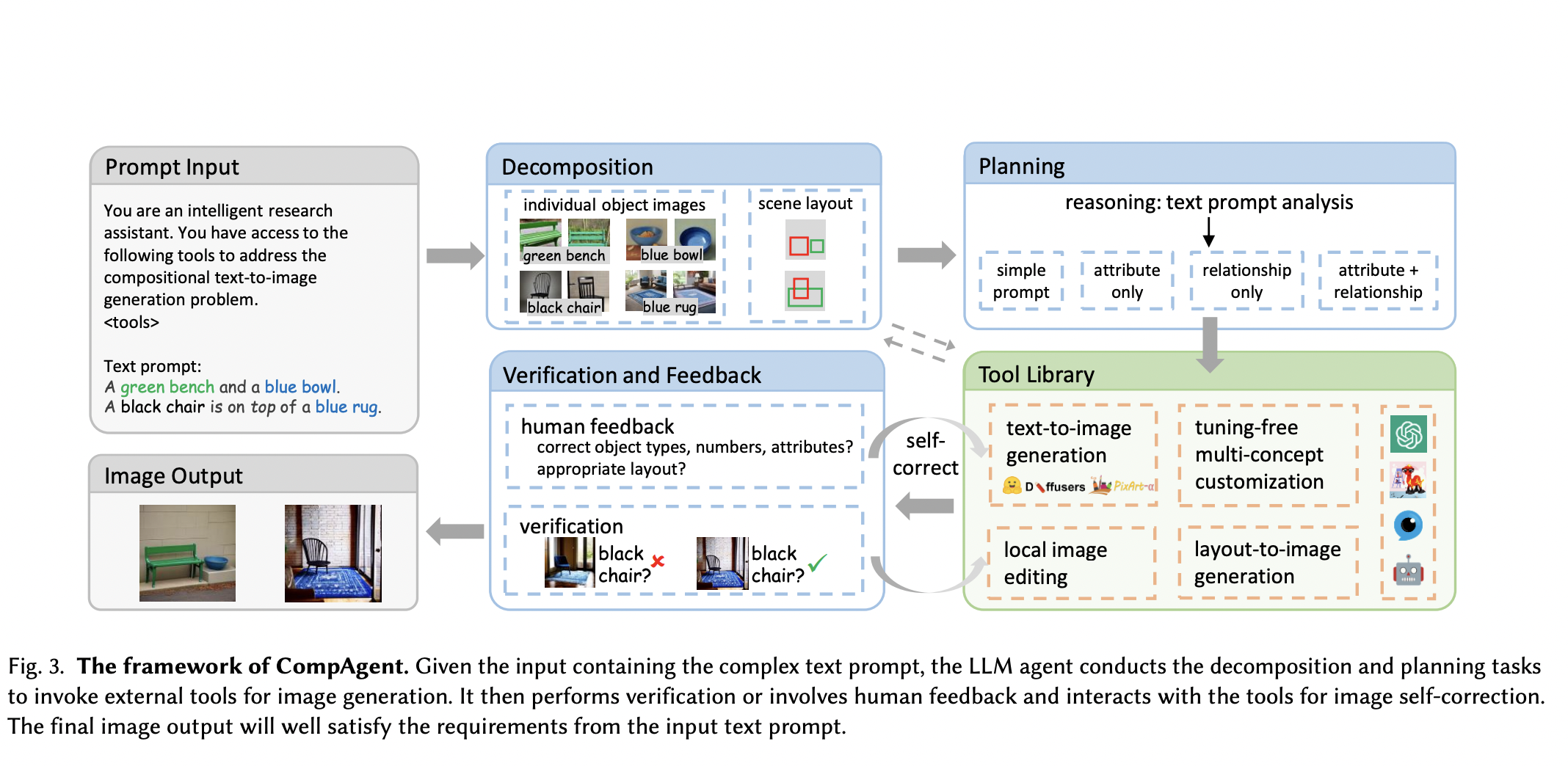
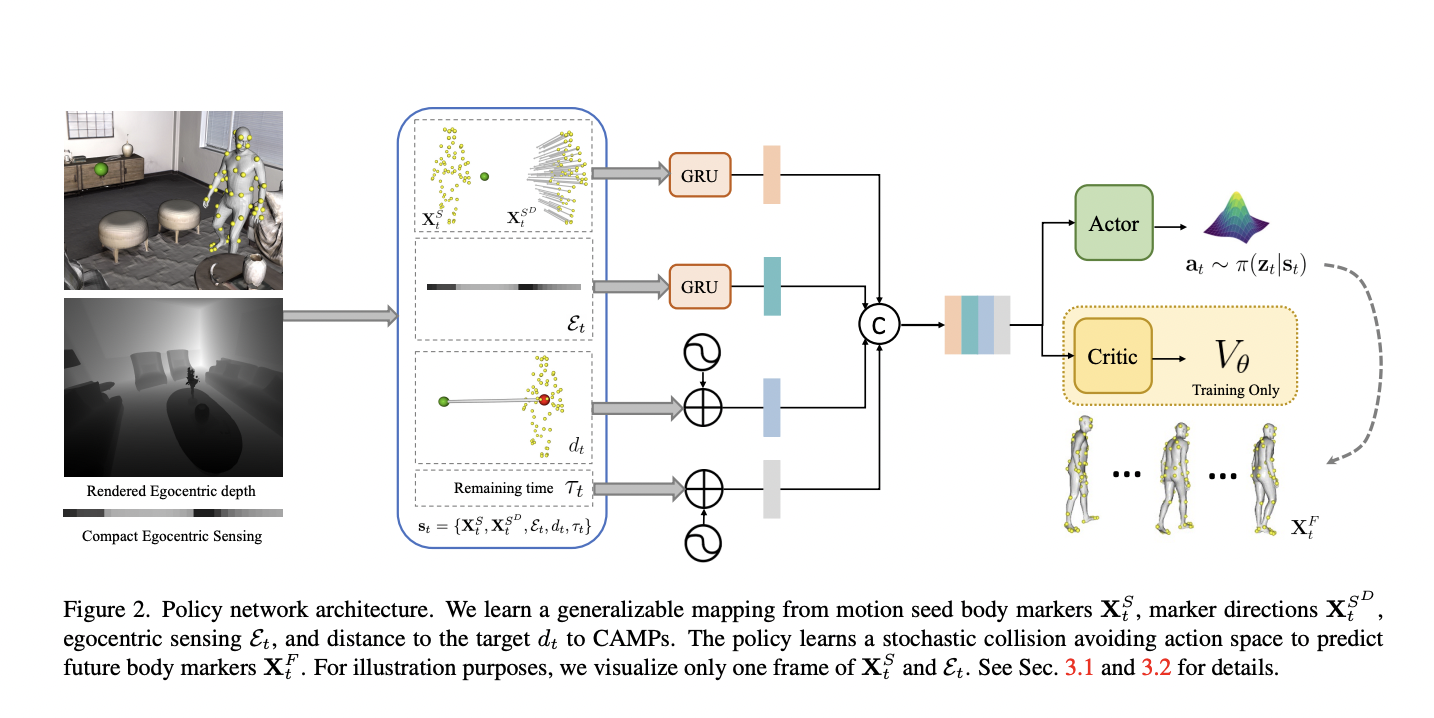
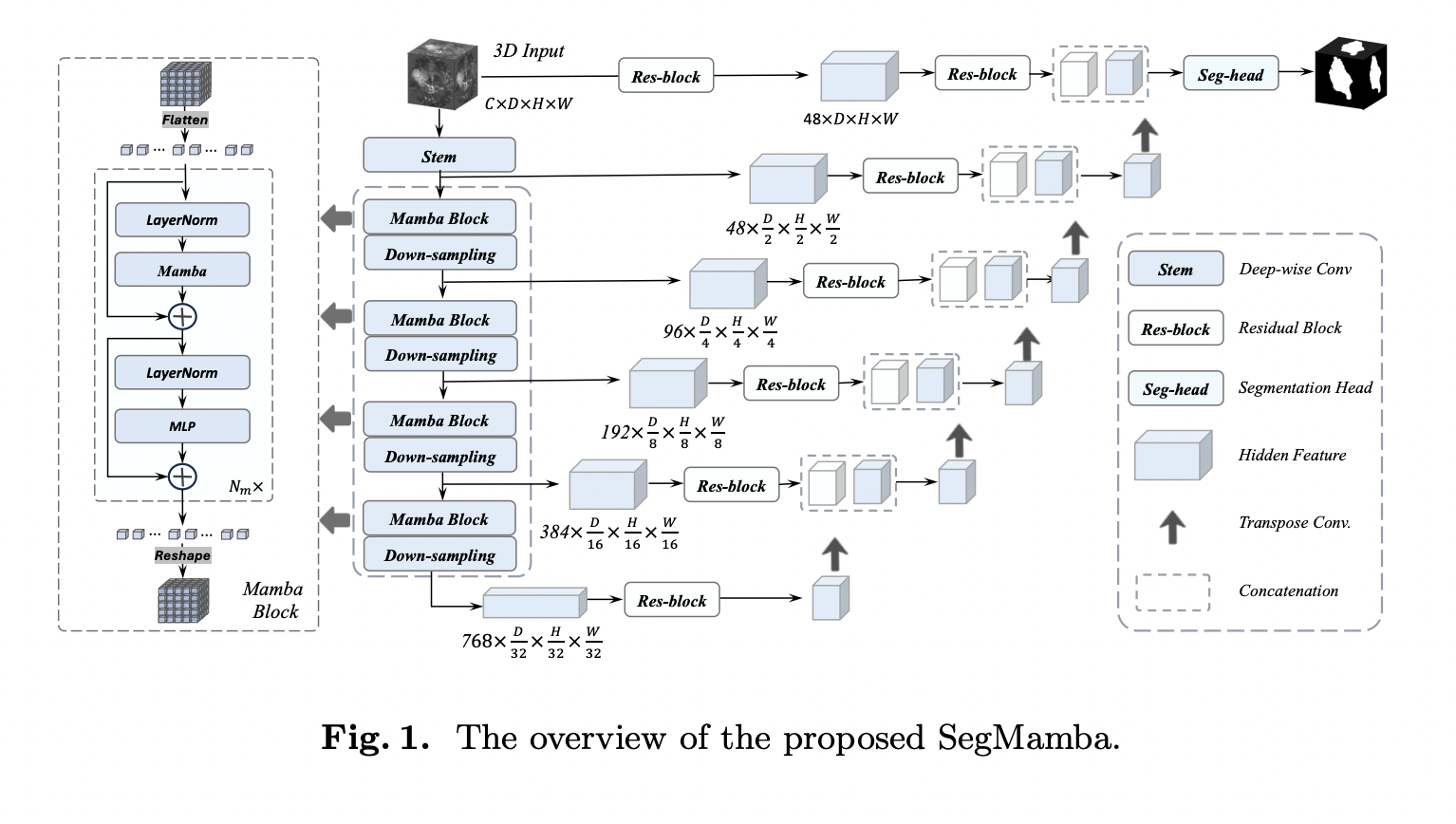
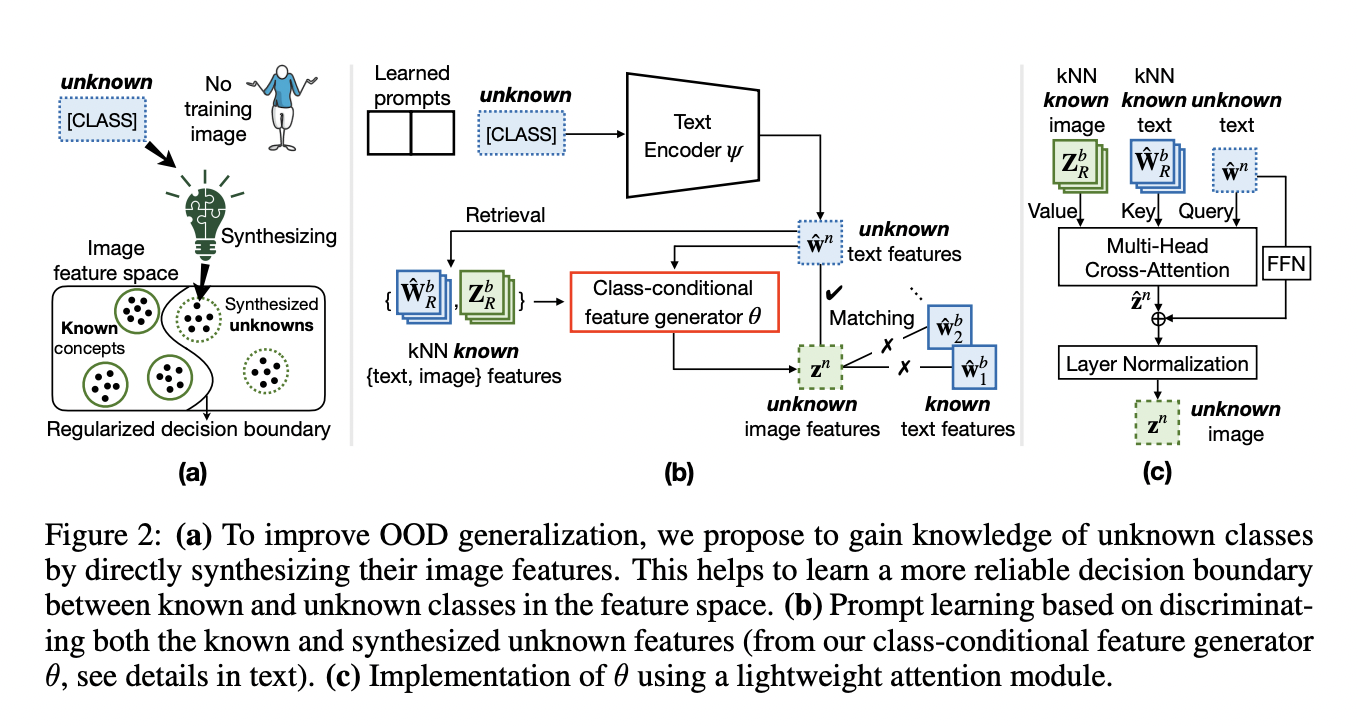
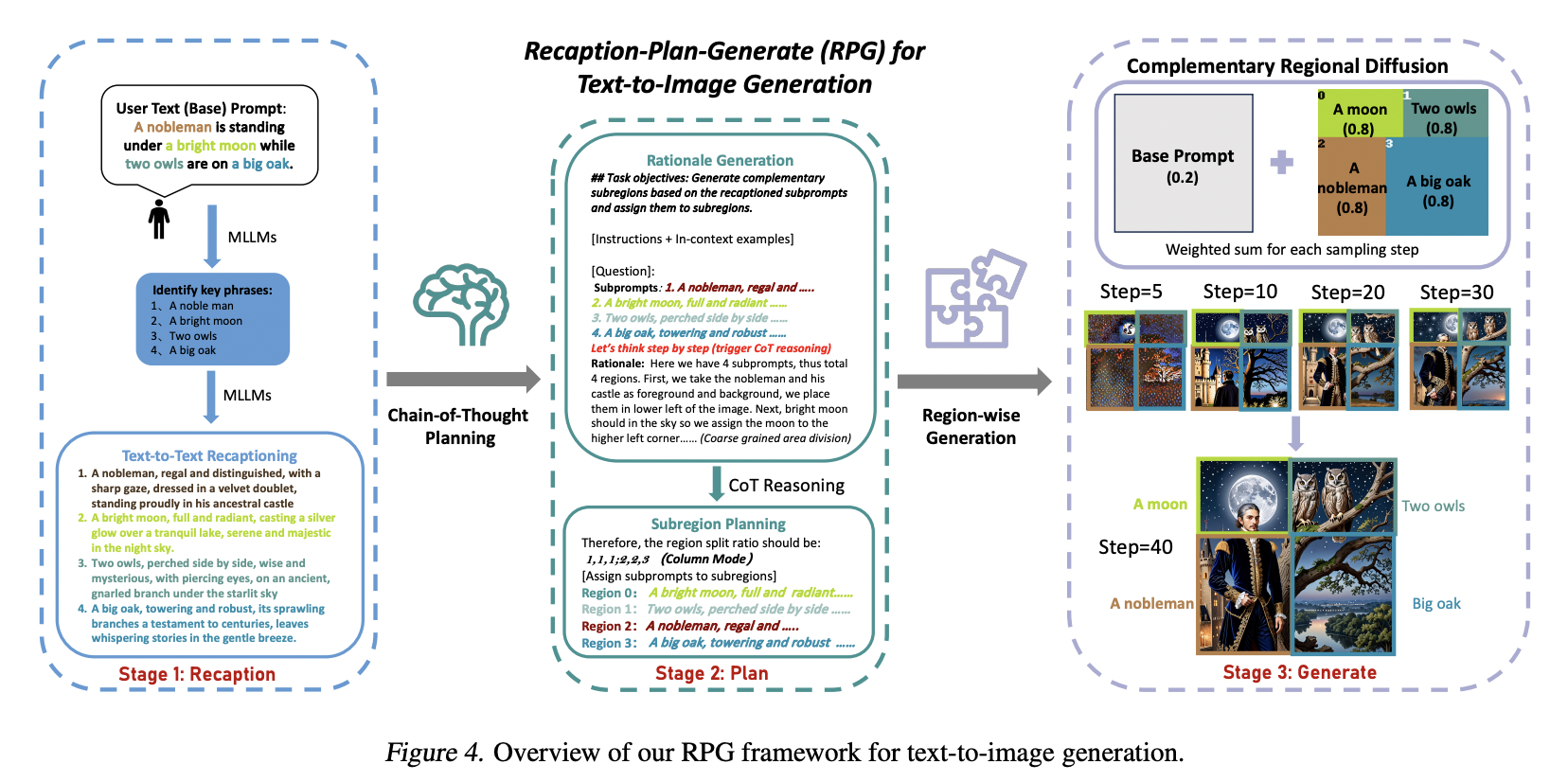
Text-to-image (T2I) generation is a rapidly evolving field within computer vision and artificial intelligence. It involves creating visual images from textual descriptions blending natural language processing and graphic visualization domains. This interdisciplinary approach has significant implications for various applications, including digital art, design, and virtual reality.
Various methods have been proposed for controllable text-to-image generation,…