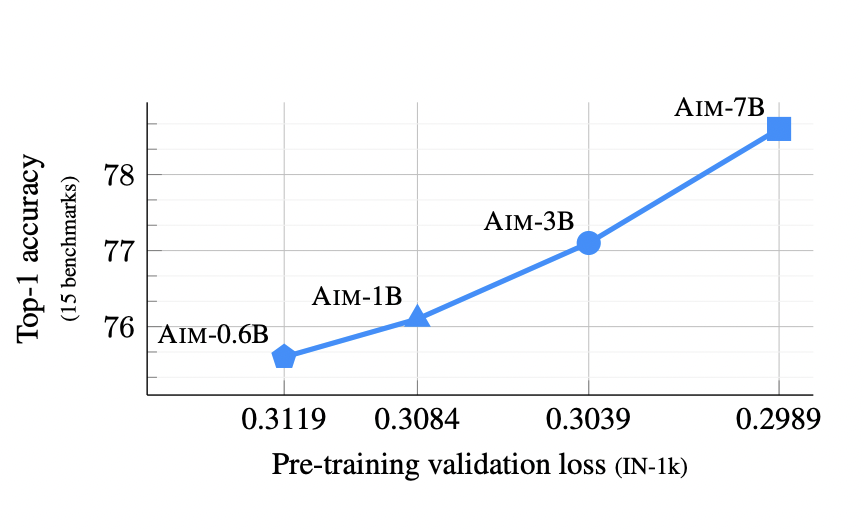
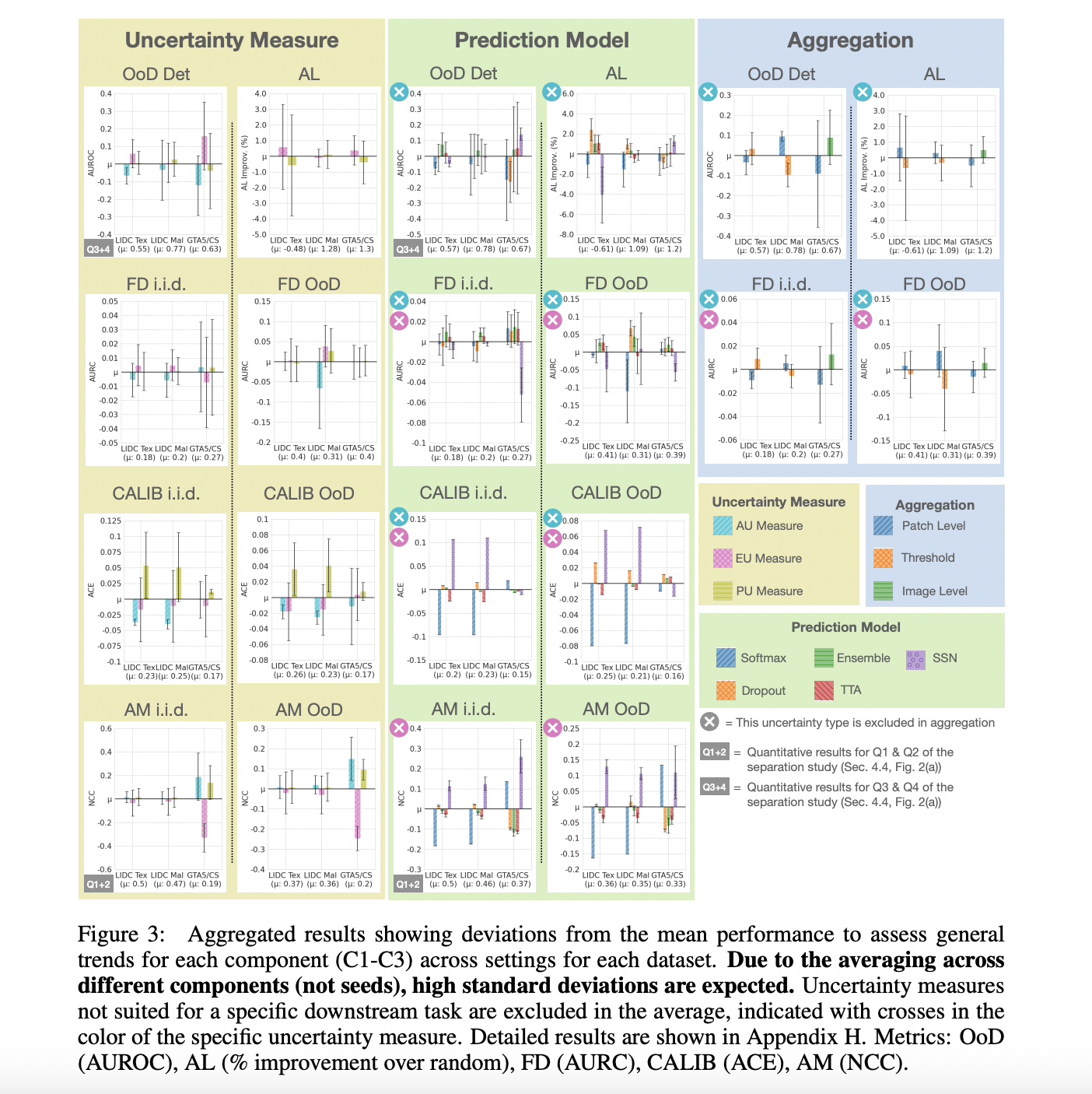
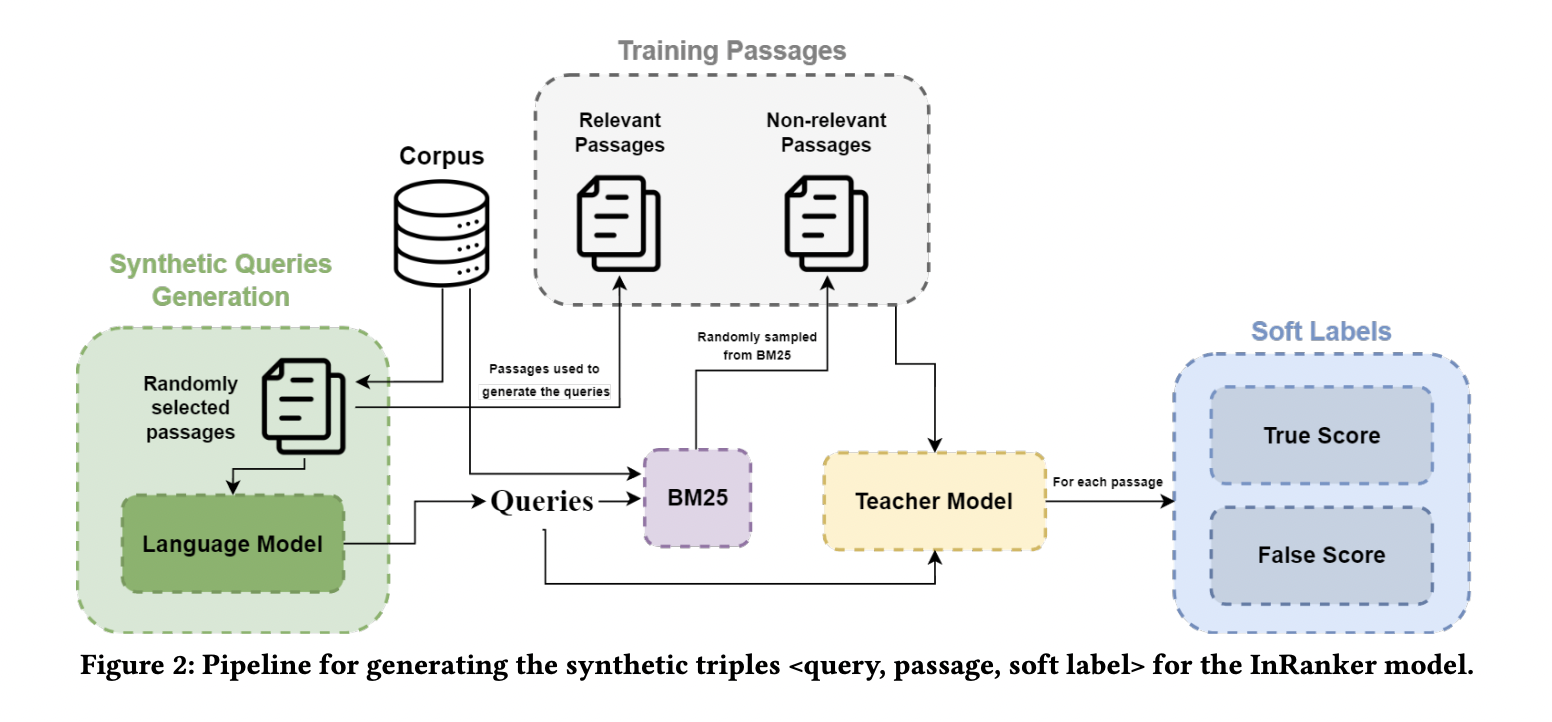
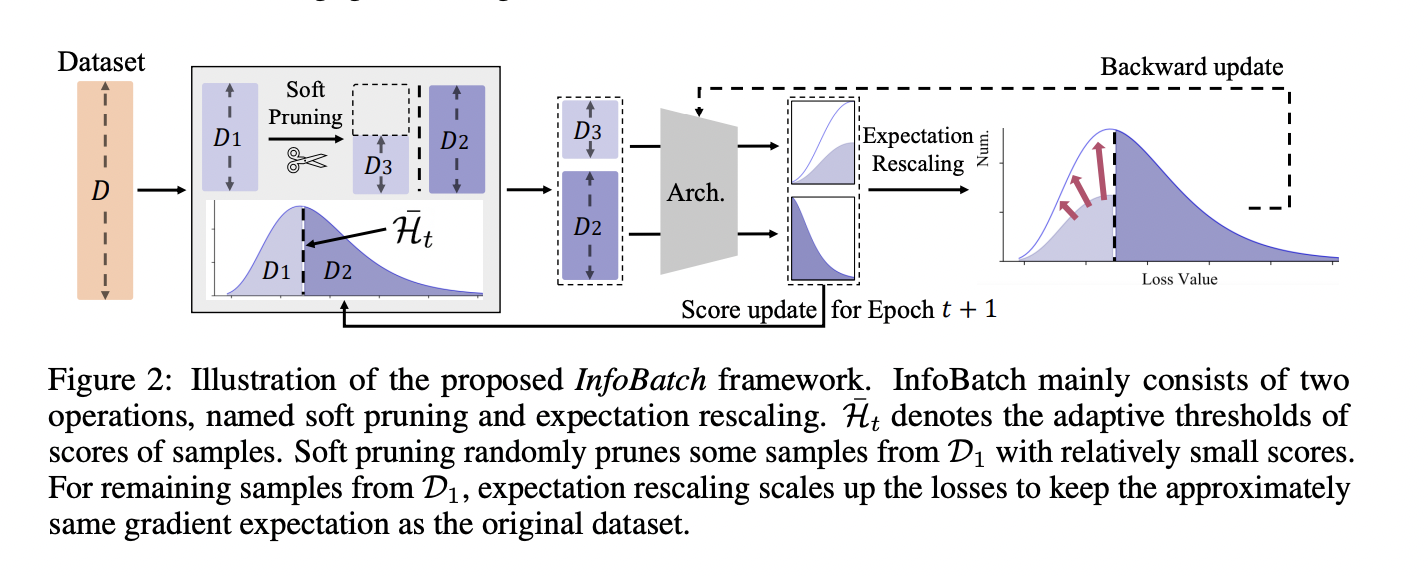
Task-agnostic model pre-training is now the norm in Natural Language Processing, driven by the recent revolution in large language models (LLMs) like ChatGPT. These models showcase proficiency in tackling intricate reasoning tasks, adhering to instructions, and serving as the backbone for widely used AI assistants. Their success is attributed to a consistent enhancement in performance…