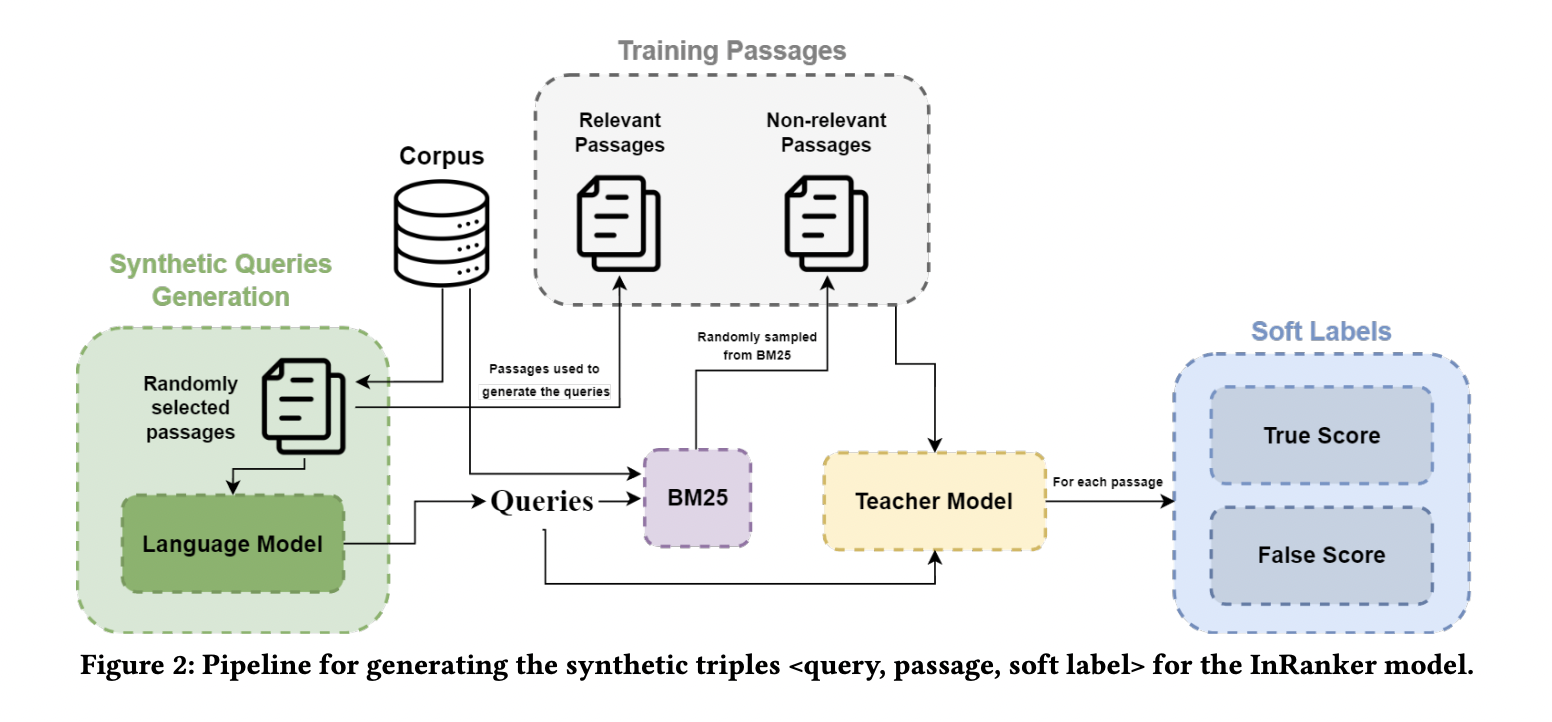
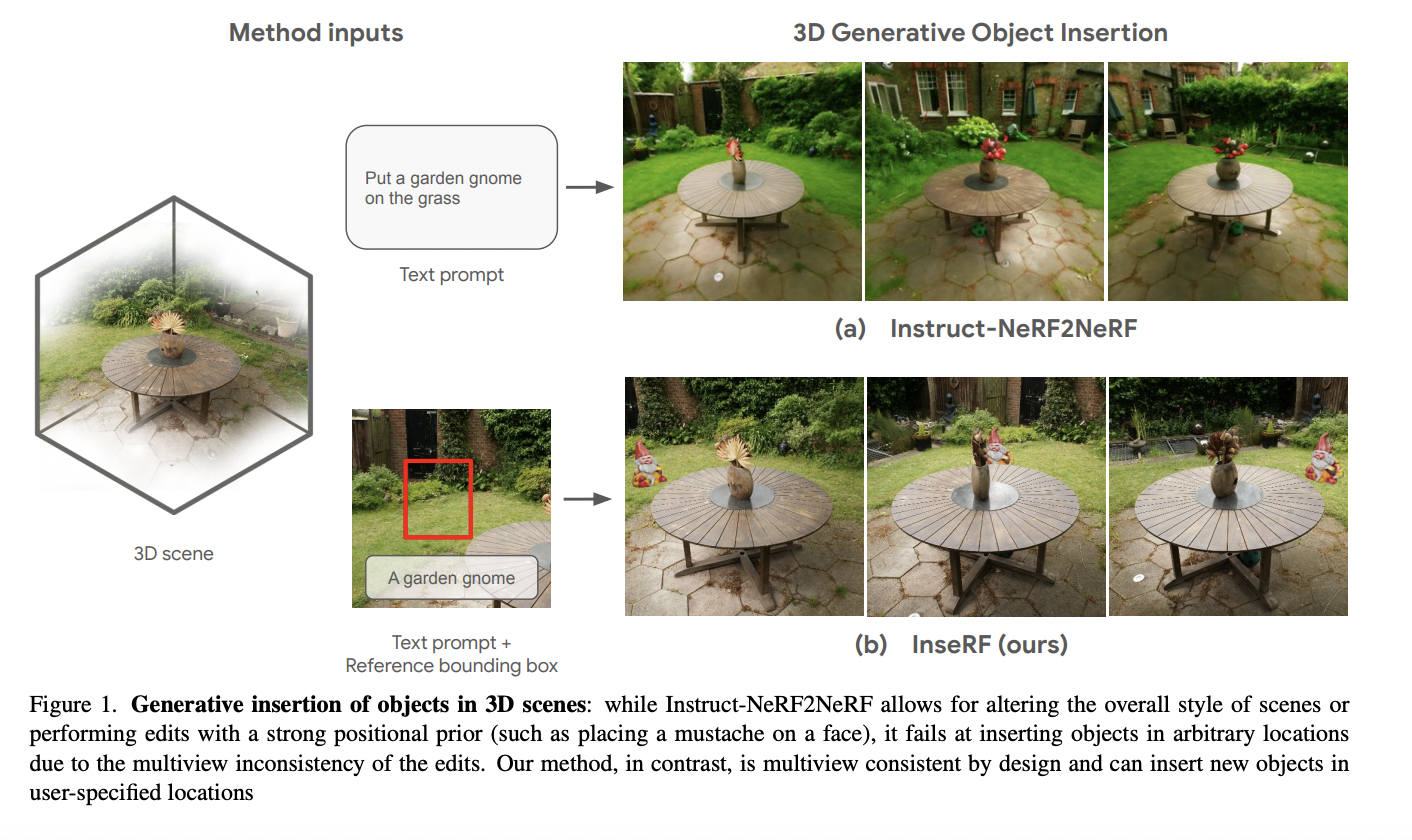
The practical deployment of multi-billion parameter neural rankers in real-world systems poses a significant challenge in information retrieval (IR). These advanced neural rankers demonstrate high effectiveness but are hampered by their substantial computational requirements for inference, making them impractical for production use. This dilemma poses a critical problem in IR, as it is necessary to…