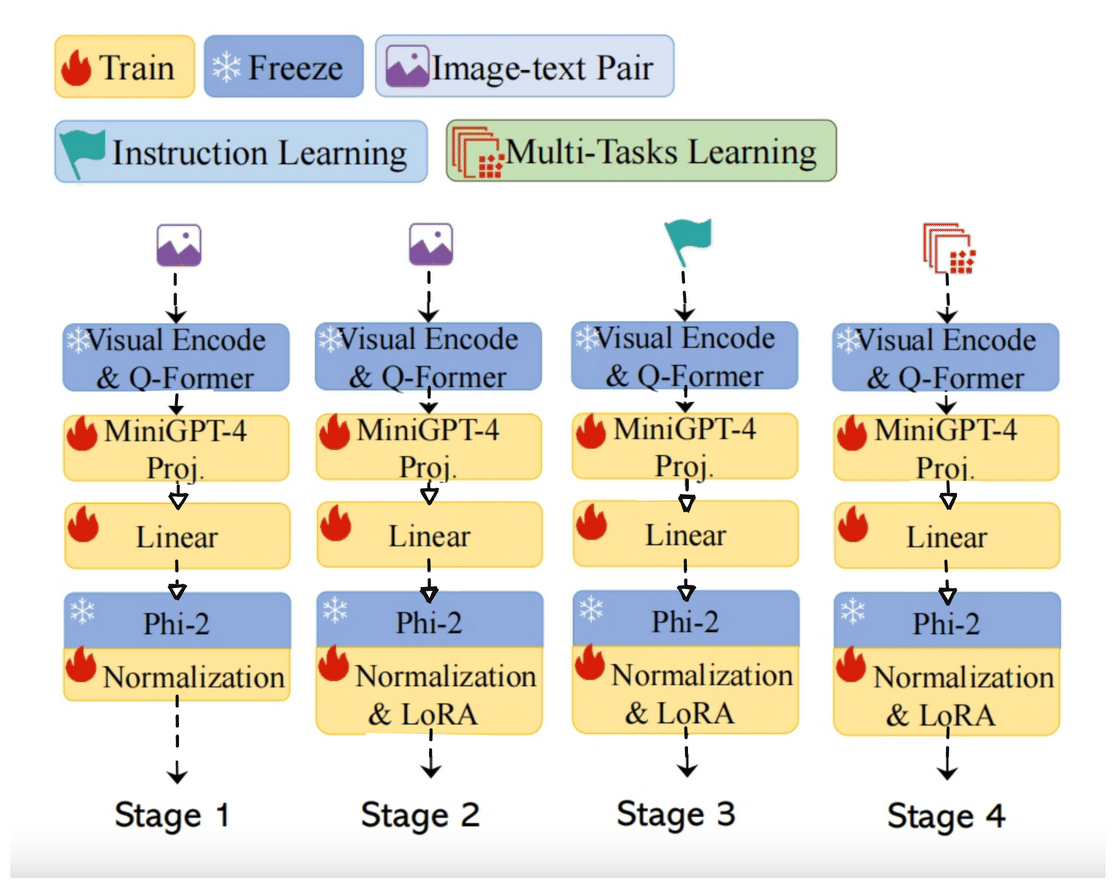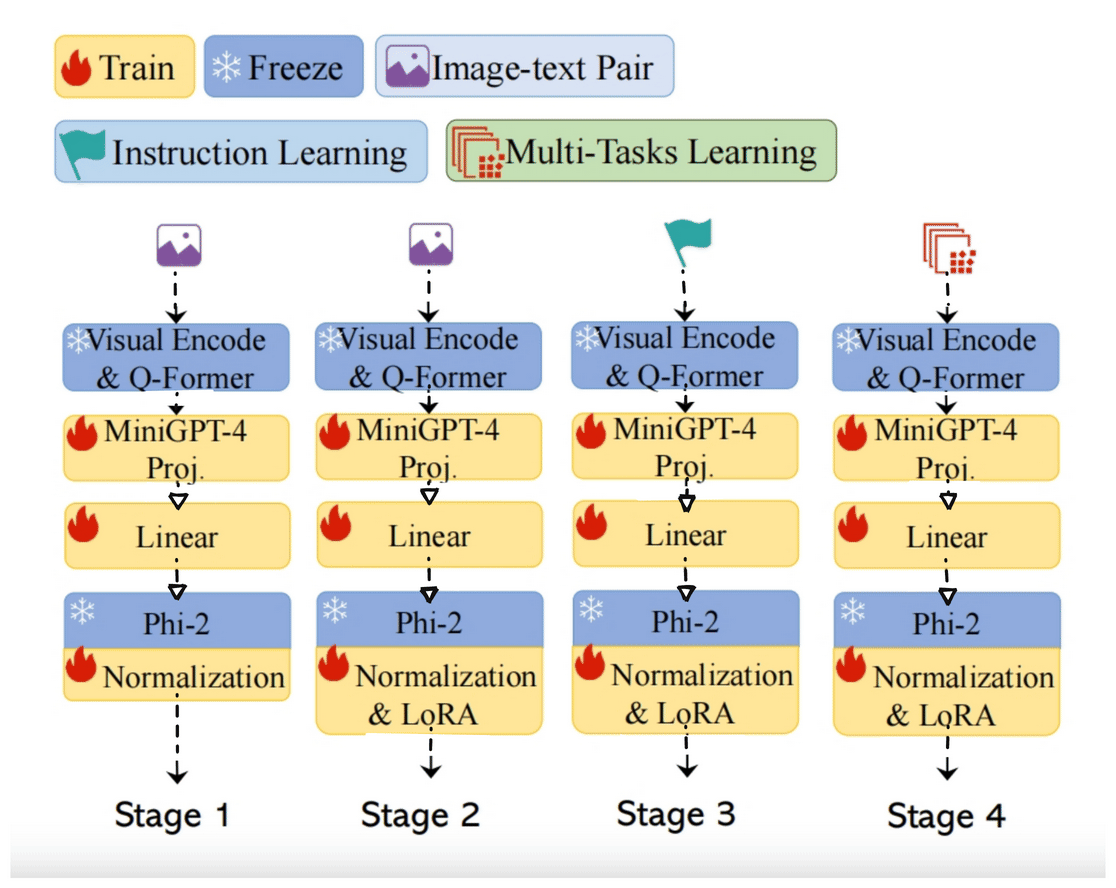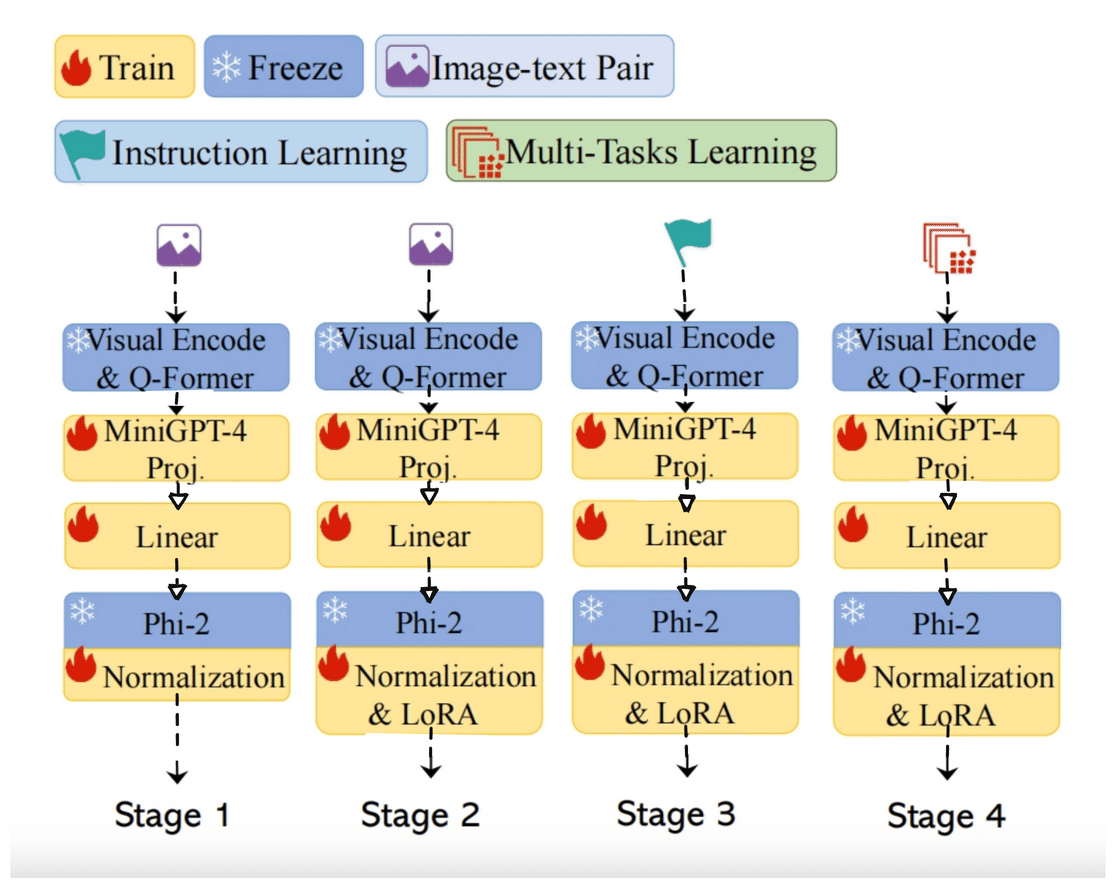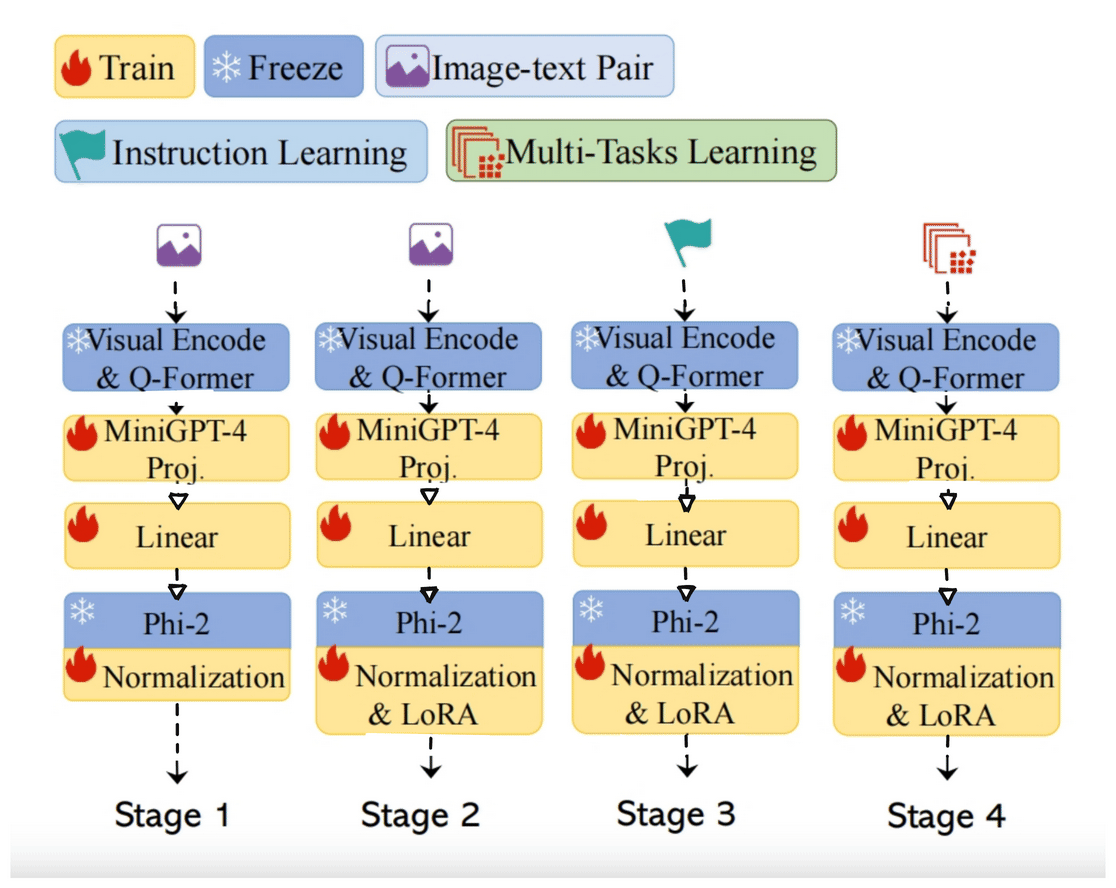
Distinguishing fine image boundaries, particularly in noisy or low-resolution scenarios, remains formidable. Traditional approaches, heavily reliant on human annotations and rasterized edge representations, often need more precision and adaptability to diverse image conditions. This has spurred the development of new methodologies capable of overcoming these limitations.
A significant challenge in this domain is the robust…