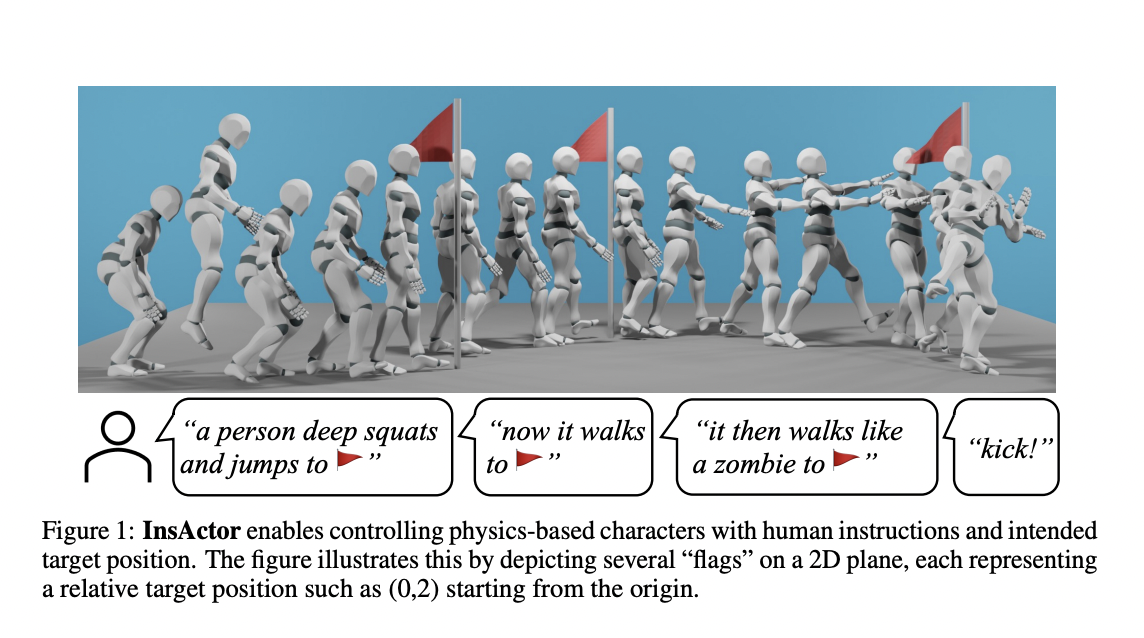
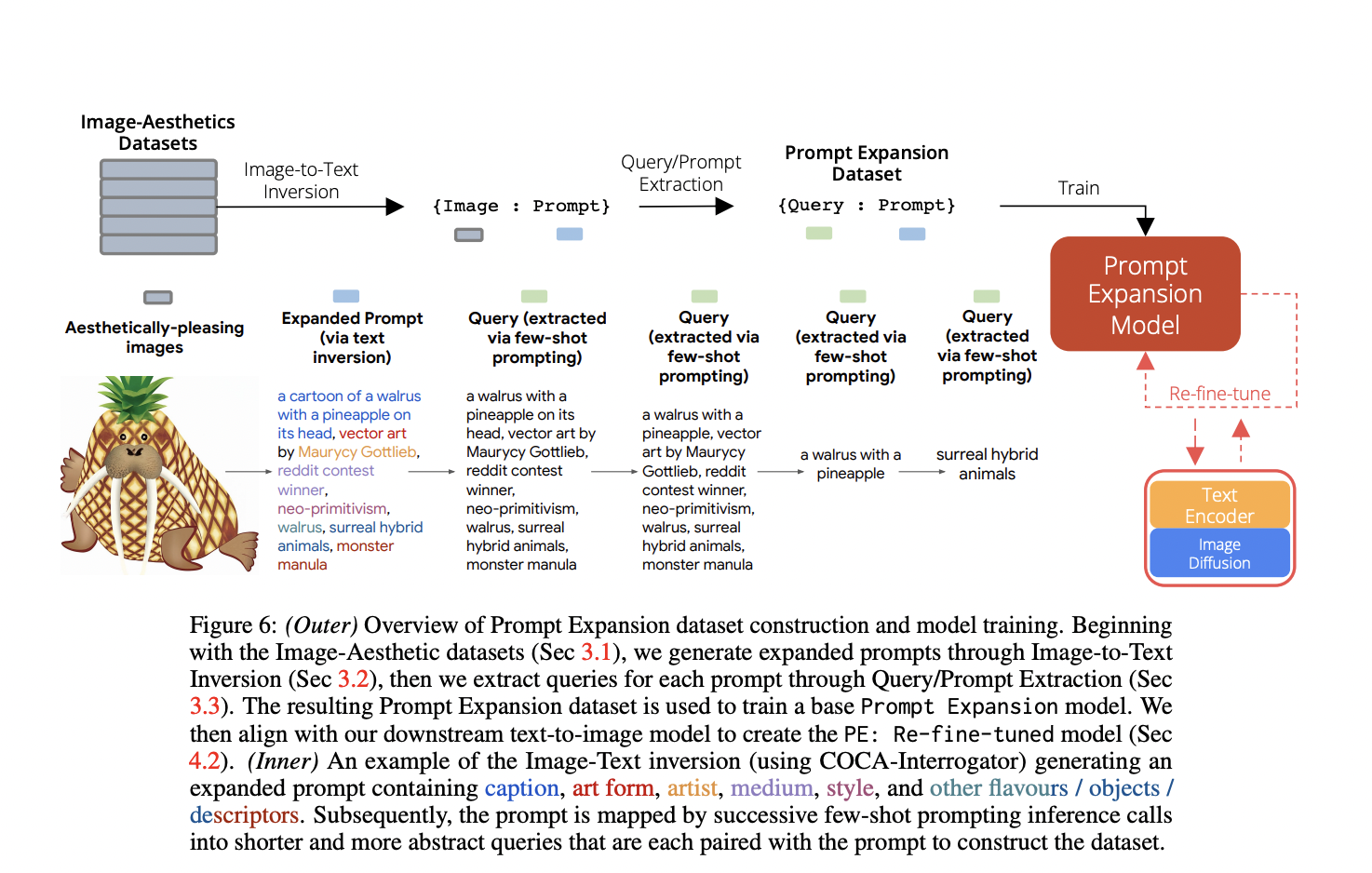
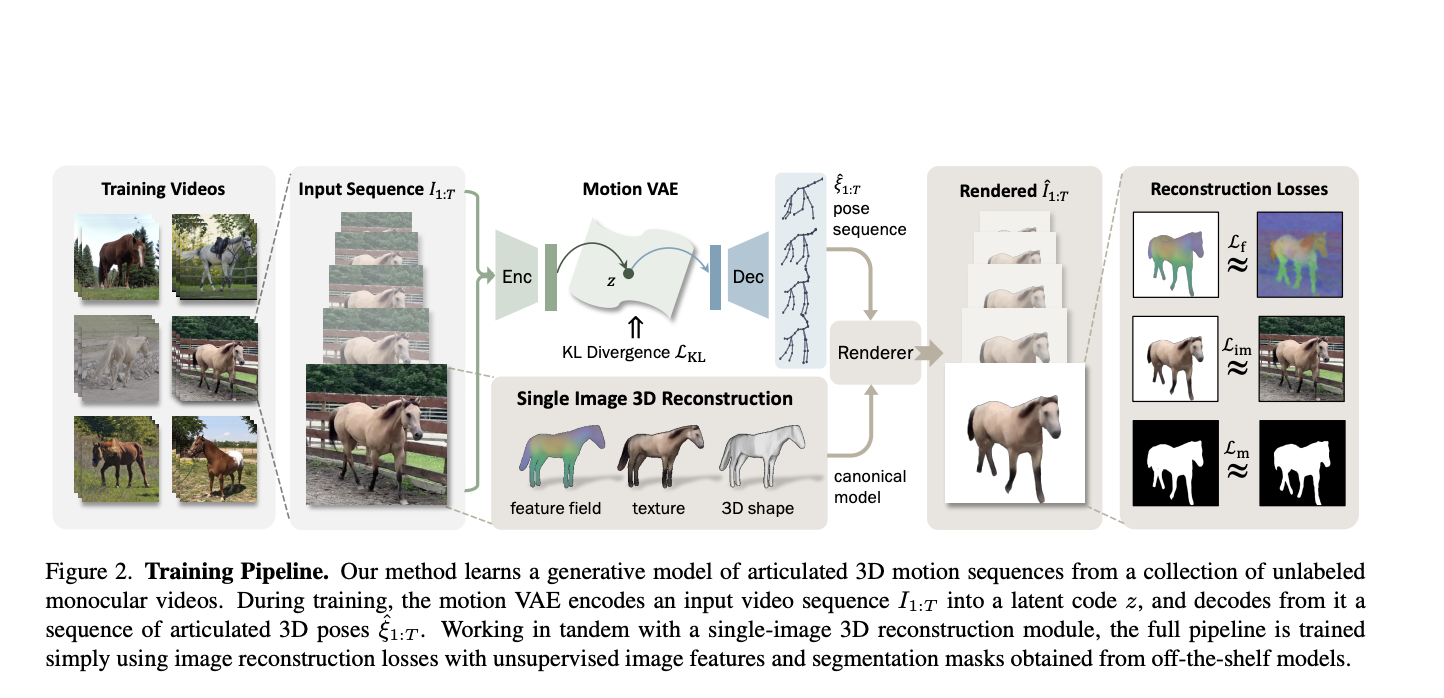
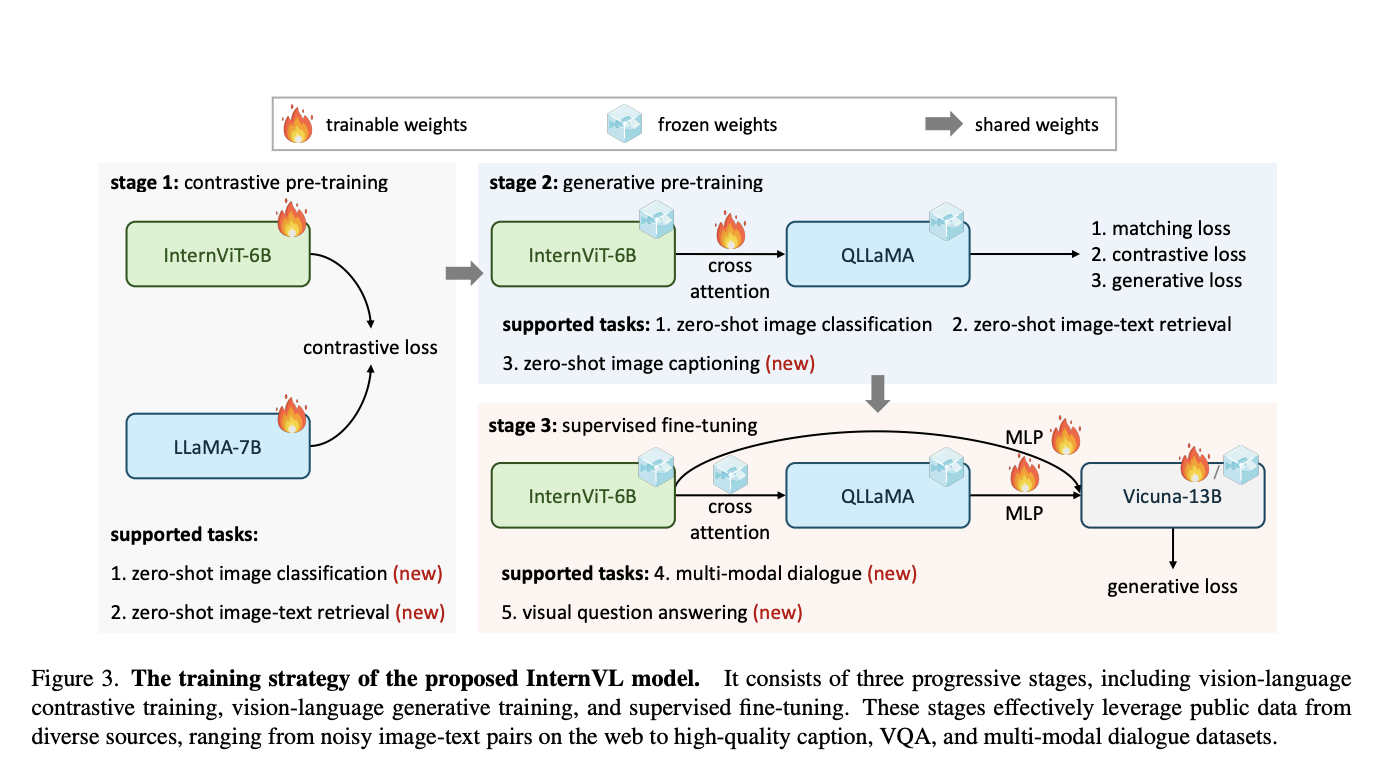
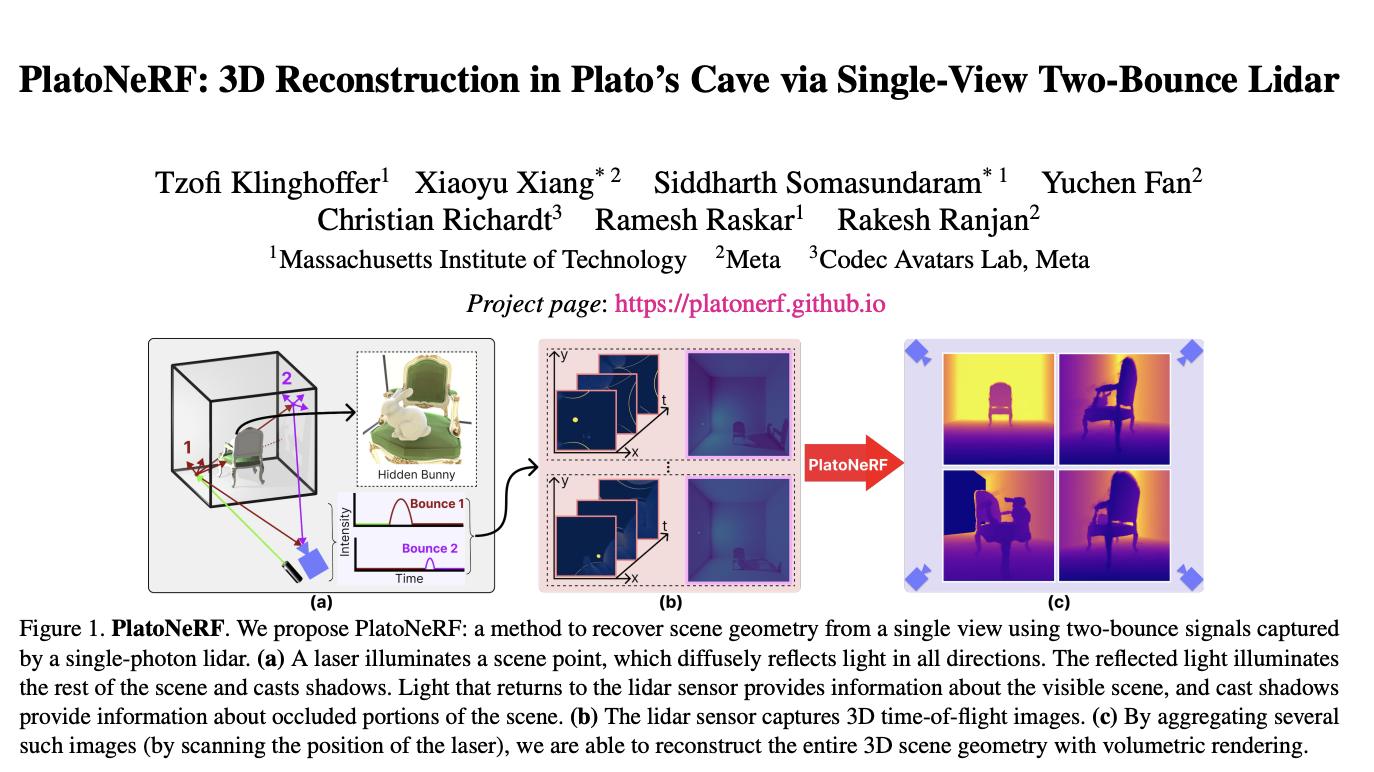
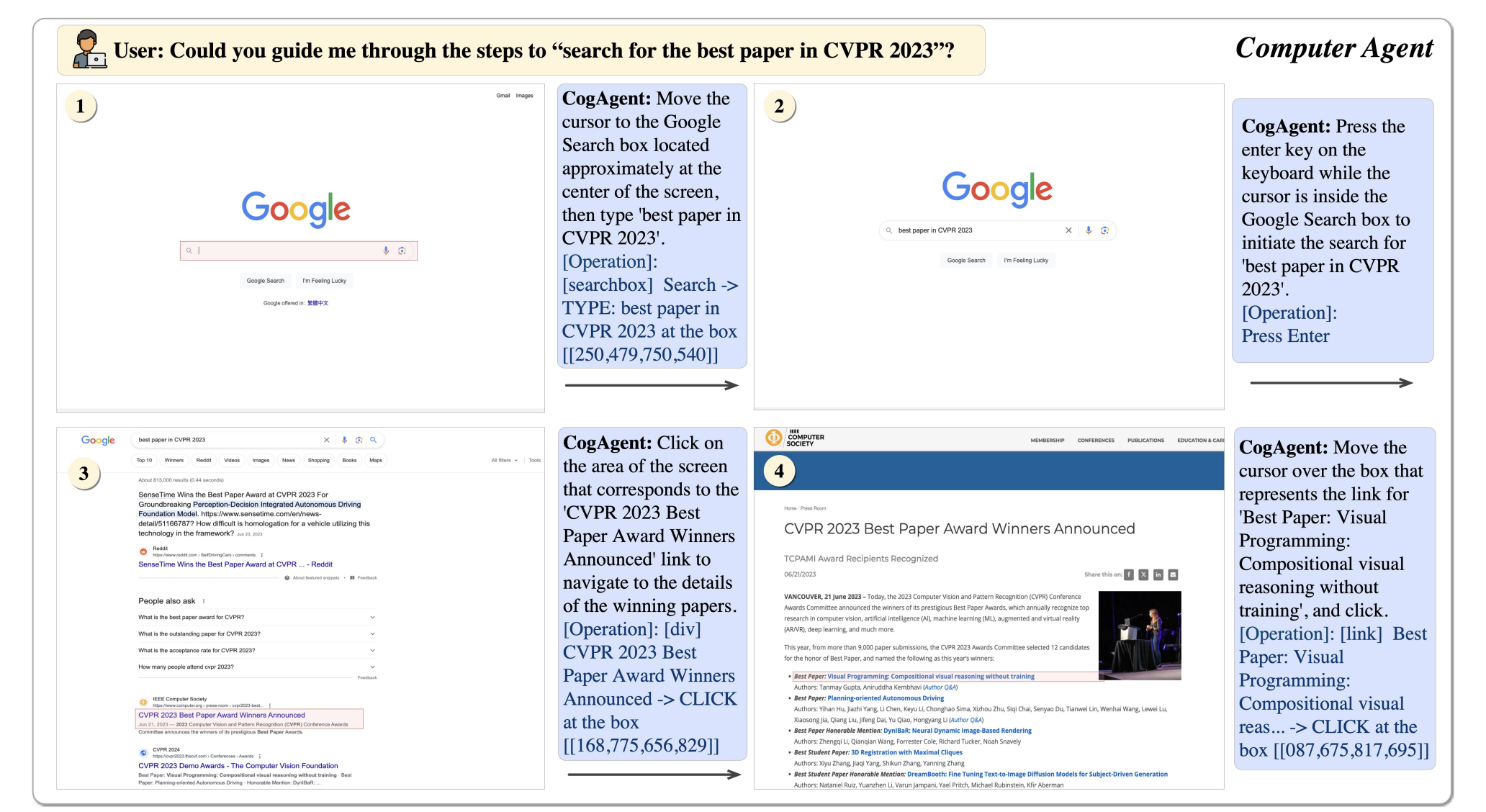
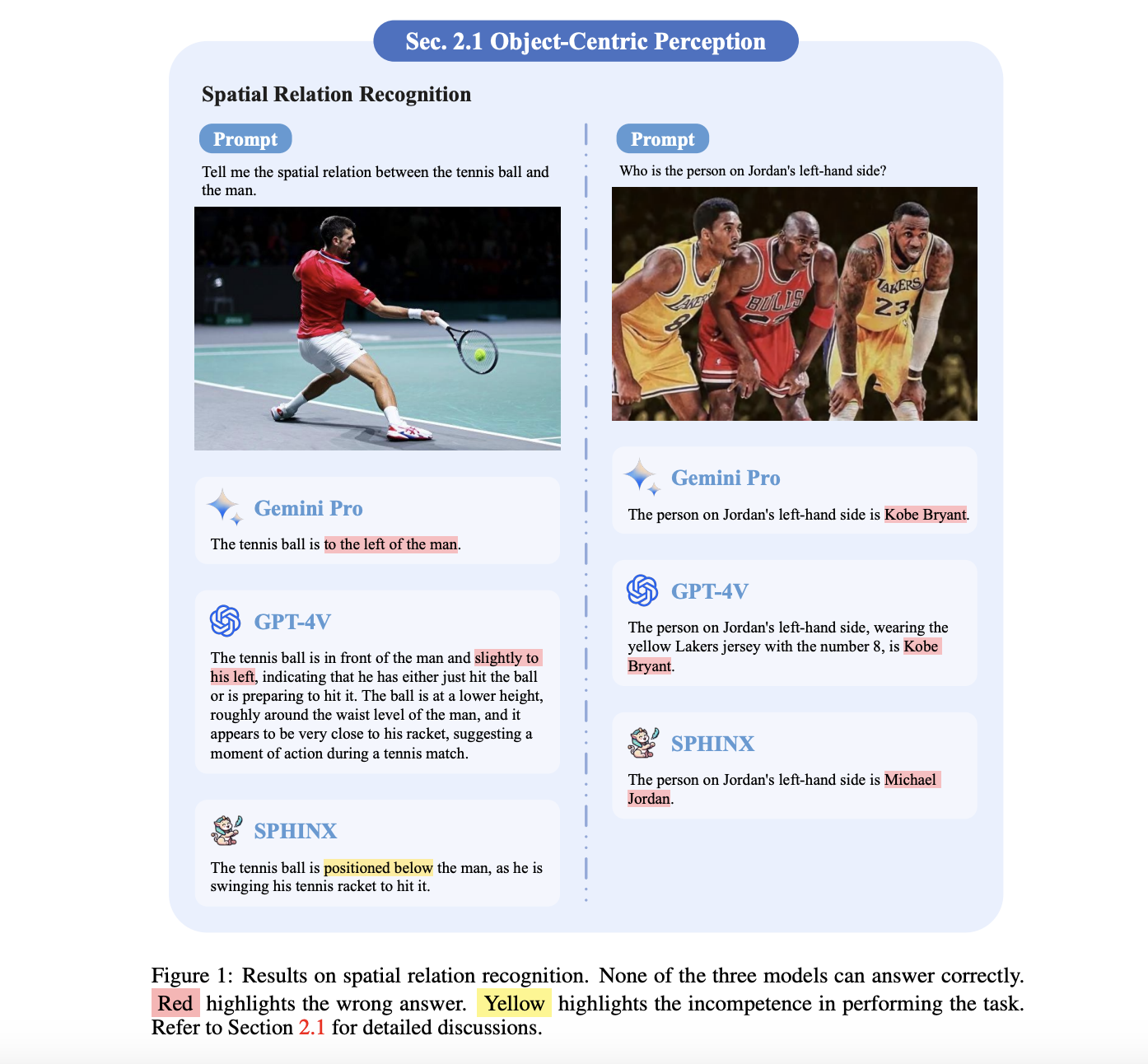
Physics-based character animation, a field at the intersection of computer graphics and physics, aims to create lifelike, responsive character movements. This domain has long been a bedrock of digital animation, seeking to replicate the complexities of real-world motion in a virtual environment. The challenge lies in the technical aspects of animation and in capturing the…