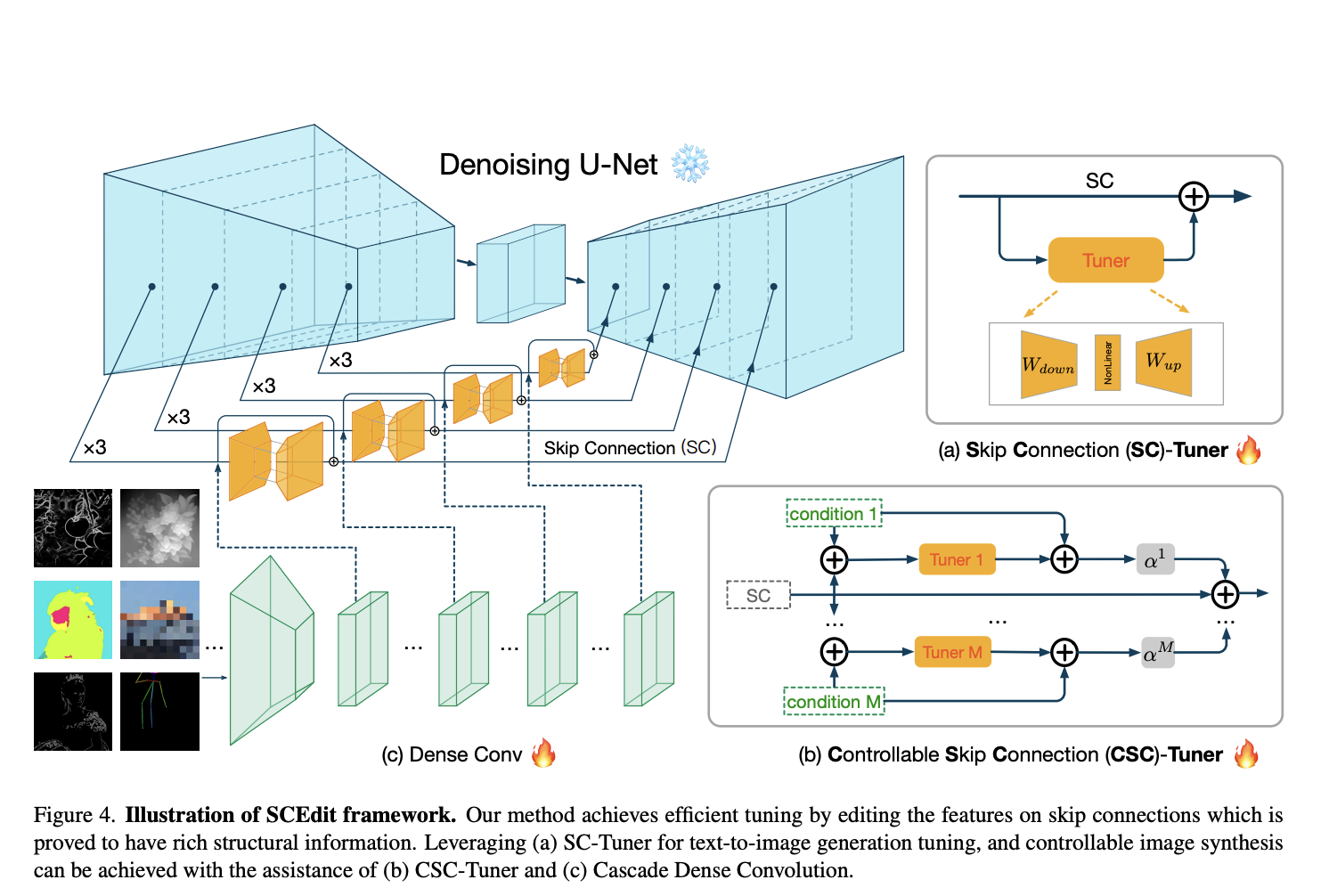
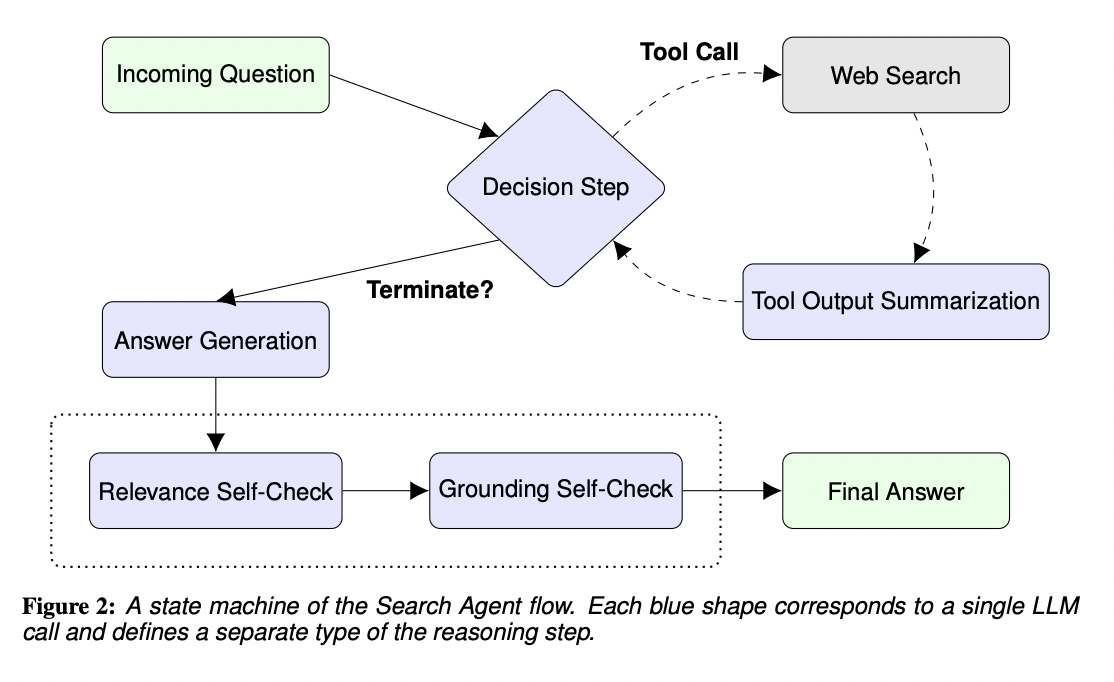
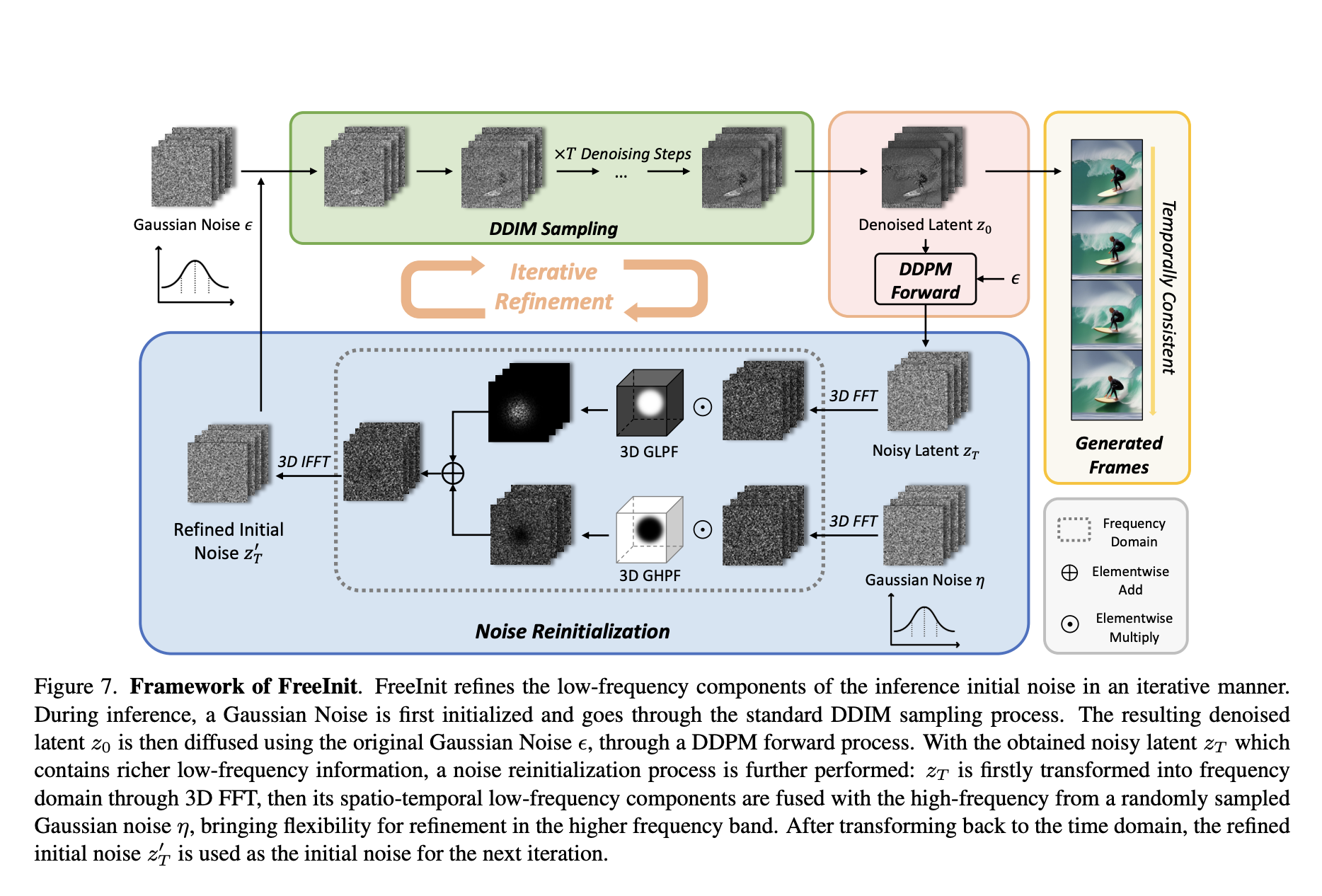
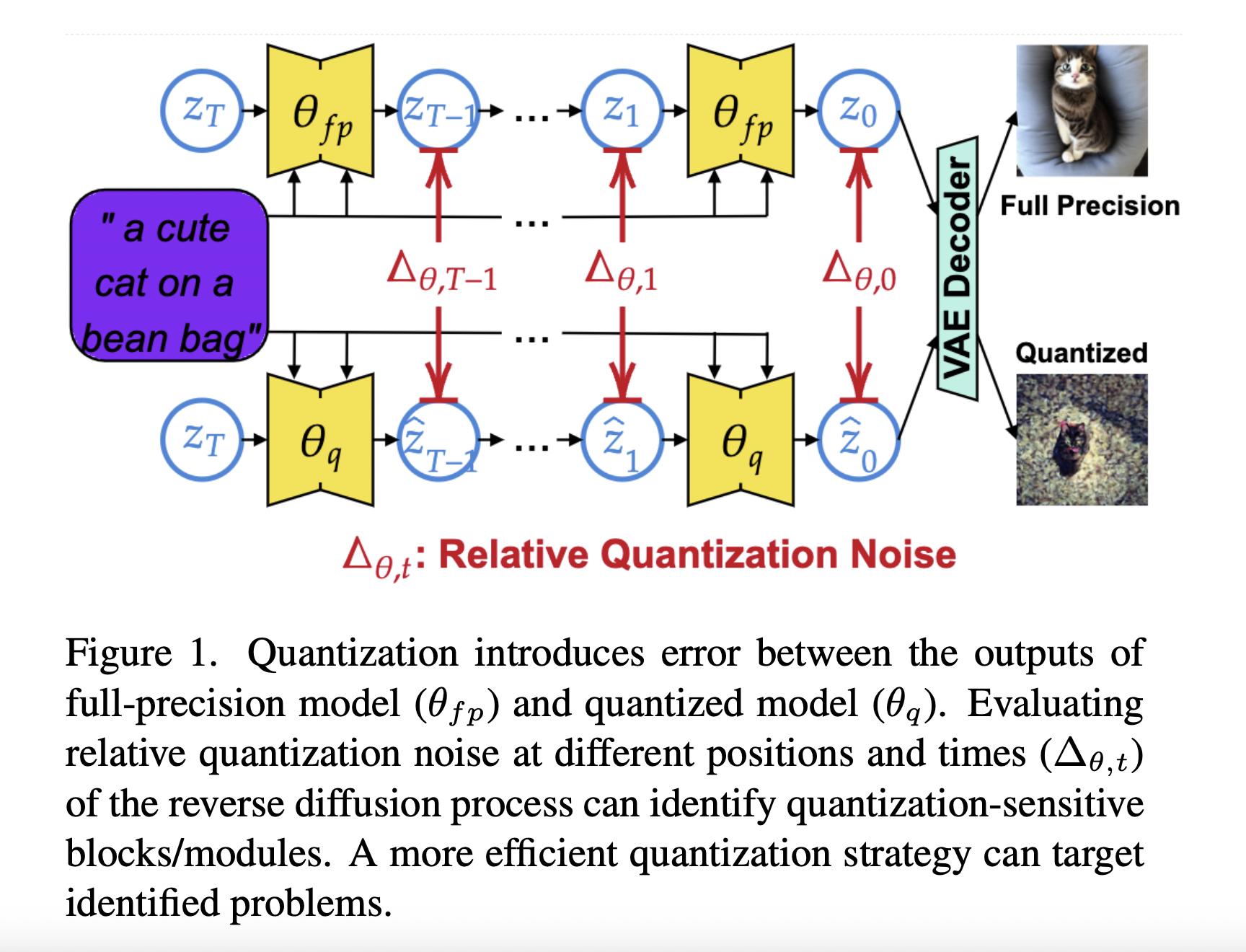
Addressing the challenge of efficient and controllable image synthesis, the Alibaba research team introduces a novel framework in their recent paper. The central problem revolves around the need for a method that generates high-quality images and allows precise control over the synthesis process, accommodating diverse conditional inputs. The existing methods in image synthesis, such as…