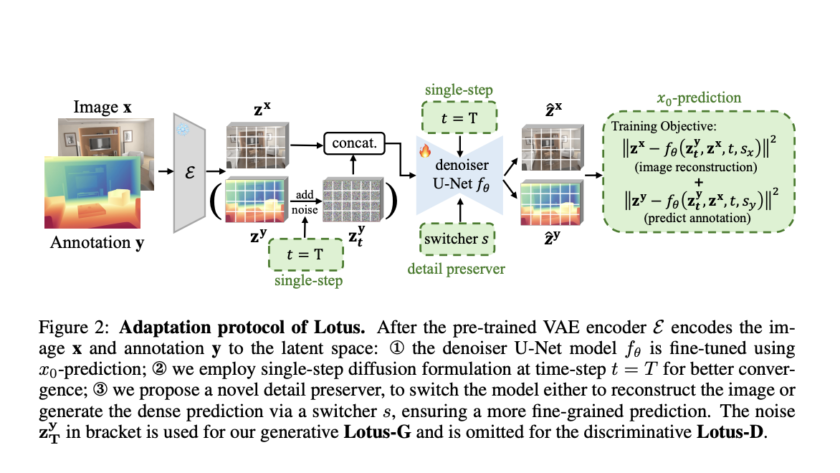
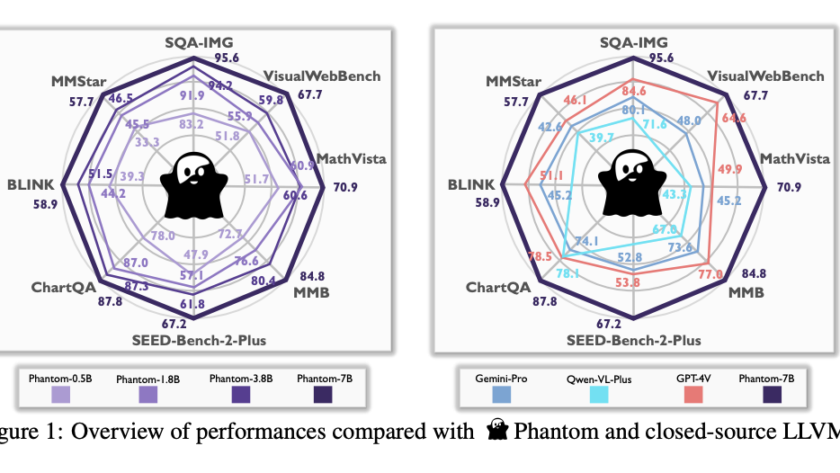
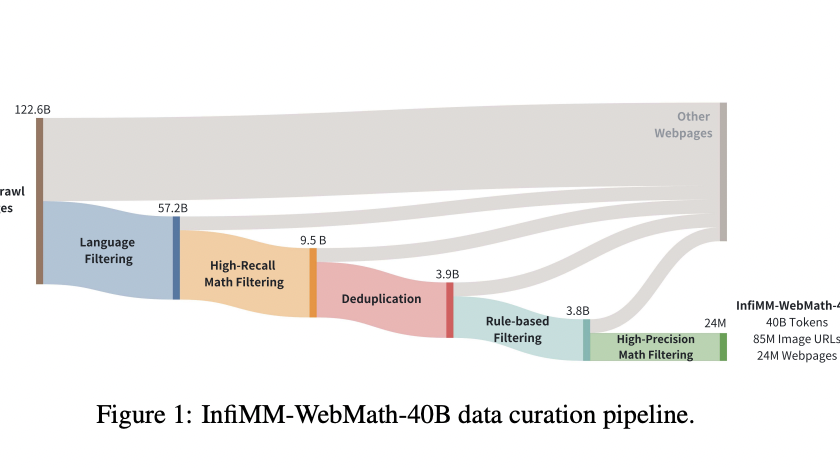
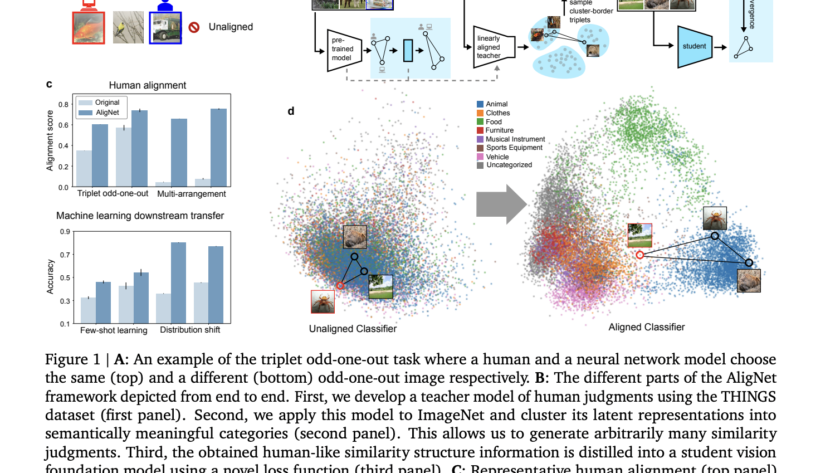
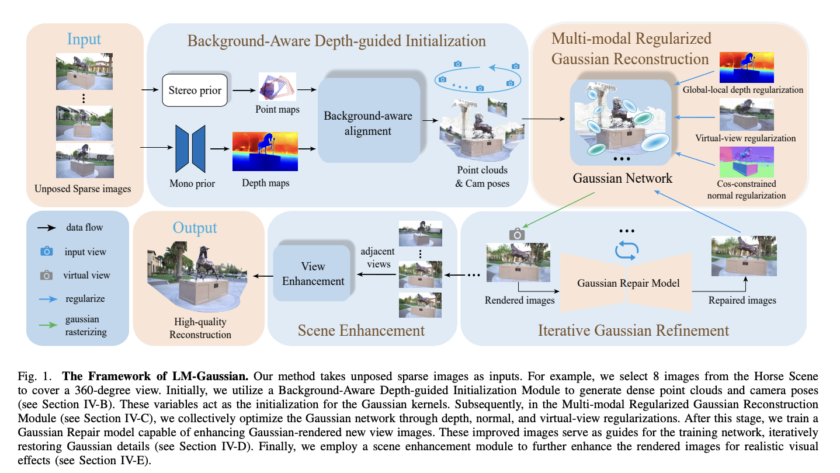
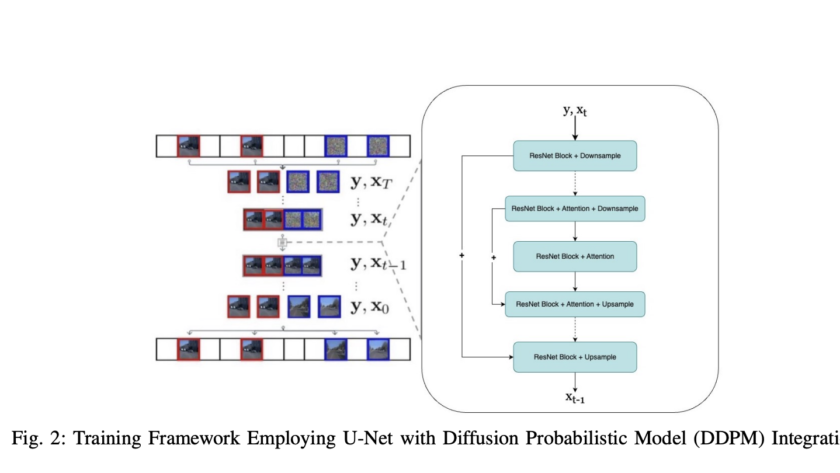
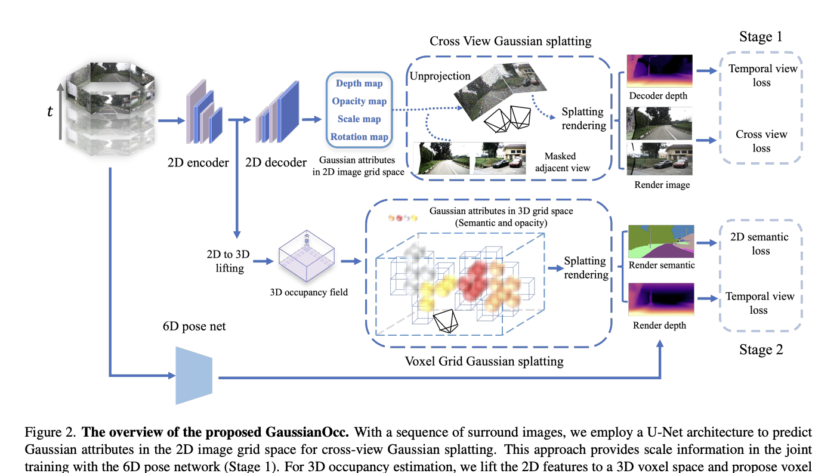
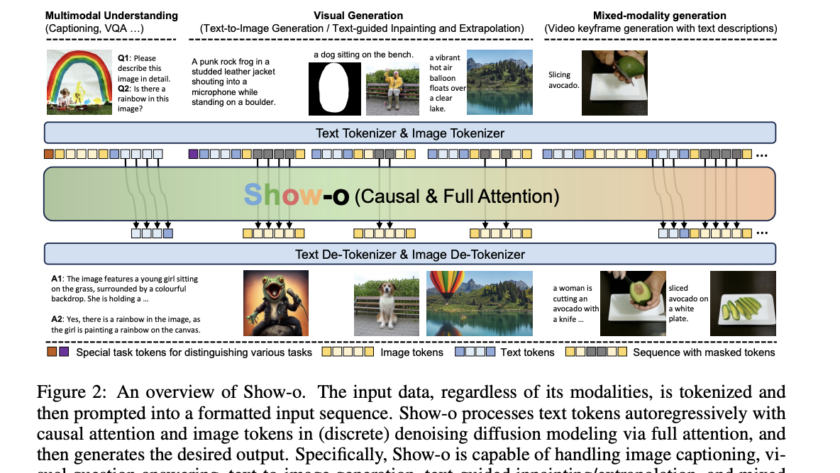
Dense geometry prediction in computer vision involves estimating properties like depth and surface normals for each pixel in an image. Accurate geometry prediction is critical for applications such as robotics, autonomous driving, and augmented reality, but current methods often require extensive training on labeled datasets and struggle to generalize across diverse tasks.
Existing methods for…