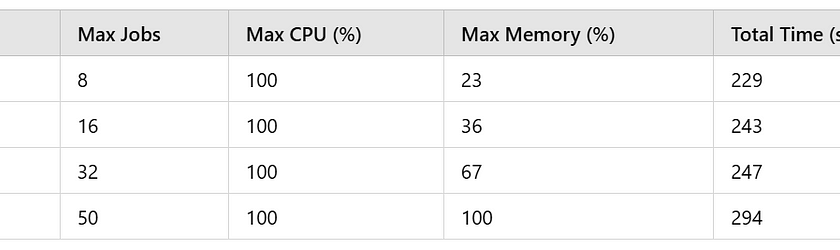
As AI models continue to increase in scope and accuracy, even tasks once dominated by traditional algorithms are gradually being replaced by Deep Learning models. Algorithmic pipelines — workflows that take an input, process it through a series of algorithms, and produce an output — increasingly rely on one or more AI-based components. These AI…